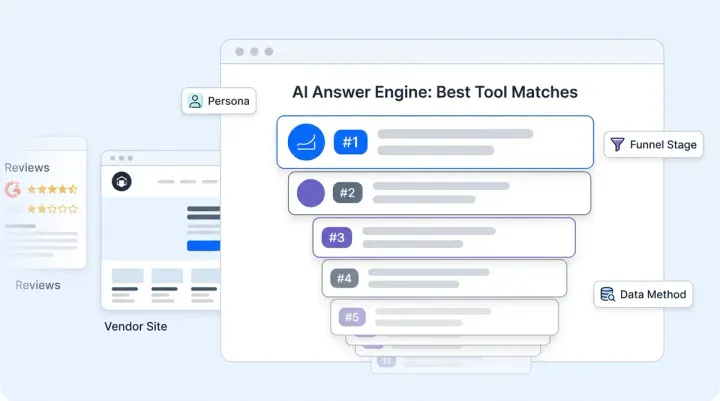
A shopper asks your AI: "I bought the Pro Plan last month. Can I get a refund if I downgrade?" A vector database finds three chunks: one about the Pro Plan's features, one about your general refund policy, and one about downgrade steps. Each chunk is semantically relevant. None of them says whether the refund policy actually applies to Pro Plan downgrades.
Alhena's knowledge graph answers this in two hops: Pro Plan → GOVERNED_BY → Refund Policy → APPLIES_TO → Downgrade. No ambiguity. No hoping the LLM stitches three chunks together correctly.
This post covers the real architecture behind that answer, and how you can optimize your AI's accuracy: how the graph gets built, how it's queried, and the six tools and capabilities it uses that a vector database can't, and why this solution matters for any online retail chatbot, and the use cases that benefit most.
The Limitation of Vector-Only RAG
Vector databases and vector search convert your content into embeddings and finds semantically similar text. It's fast, handles fuzzy queries and semantic search well, and works for single-hop lookups like "What's your return policy?" But vector databases treat your knowledge base as a flat bag of text chunks. They have no concept of structure.
Three problems show up in production:
- Synonym blindness. "Pro Plan," "Pro subscription," and "our paid tier" live in three separate chunks. The vector DB returns all three and hopes the LLM figures out they're the same thing.
- No multi-hop reasoning. Questions like "What policy governs refunds for Pro Plan downgrades?" require traversing a chain of relationships. A vector DB has to hope one chunk mentions both "Pro Plan" and "refund policy" in the same paragraph.
- No typed structure. "Apple" the company and "Apple" the fruit have near-identical embeddings. Without type labels, the vector DB can't tell them apart.
FalkorDB's 2025 benchmark using the Diffbot dataset showed vector search accuracy drops to 0% when queries involve more than five entities. For commerce and e-commerce brands, where a single question can touch products, policies, compatibility, ingredients, and sizing all at once, that's a real problem. The product data fields that matter for AI need structure, not just similarity.
What Alhena's Knowledge Graph Adds
Alhena runs a Neo4j knowledge graph for structured data alongside Qdrant vector search. The graph builds an explicit structured layer on top of your raw content: interconnected entities (the nouns, like products, policies, features, attributes, organizations) and relationships (the verbs, like requires, replaces, belongs_to, governed_by). Each relationship carries a strength score from 1 to 10, quantifying how tight the connection is.
For structured spreadsheet data specifically, Sheet Search gives the agent a table-aware lookup tool for precise row-level answers.
At query time, both systems are consulted in parallel and results are merged before the LLM sees them. The graph doesn't replace vector search. It adds a structural layer of understanding that vector hits alone don't have.
How the Graph Gets Built: A Six-Stage Pipeline
Stage 1: Domain-Adaptive Config Tuning. Before extracting anything, Alhena samples chunks from your training data and asks an LLM to determine your domain (e-commerce, SaaS support, consumer electronics). From that, it auto-generates the set of entity types (PRODUCT, POLICY, FEATURE, ORGANIZATION) and relationship patterns with strength scores. The schema isn't hardcoded. A camping-gear retailer's graph has different node types than a B2B SaaS business's graph. This is a key difference from platforms that use a generic, one-size-fits-all ontology, and it enables use cases that rigid schemas can't handle.
Stage 2: Isolated Database Creation. Each customer gets their own isolated Neo4j database, named by bot profile and version number. Versioning lets full rebuilds happen without any downtime. Your data never mixes with another customer's graph.
Stage 3: Entity and Relationship Extraction. Documents and datasets are chunked (up to 10,000 tokens) and sent to GPT-4o Mini, a fast extraction model, with a structured prompt. For every chunk, the model returns AI generated structured JSON containing entity names, normalized names, types, attributes, descriptions, relationship types, and strength scores. Entities are deduplicated by normalized name and type: if "Pro Plan" shows up in 40 help articles, it becomes one node whose description consolidates all 40 mentions, with every source URL tracked for provenance.
Stage 4: Description Summarization. Concatenated descriptions from multiple sources get noisy. A summarizer pass consolidates them into one coherent description per entity, preserving the important details from each source.
Stage 5: Embedding Generation. Every node and every edge gets a vector embedding via the OpenAI API's text-embedding models. This is what enables the model to perform semantic lookup into the graph itself.
Stage 6: Vector Index Creation. Neo4j's native vector index is built over the entity embeddings, enabling fast approximate nearest-neighbor search directly within the graph database.
If you're curious about how the raw documents get prepared before this pipeline runs, our post on agentic chunking covers the intelligent content segmentation that feeds into the graph builder.
How It's Queried at Runtime
The query path does something a pure vector database can't. When a shopper asks a question, the system embeds the query and runs a semantic search against the graph's entity index to find the top 20 most relevant nodes (not document chunks, but actual business objects). At inference time, Neo4j traverses the edges between those hits and returns the connected nodes along with the relationships linking them.
The result isn't a paragraph of text. It's a structured table of nodes plus the relationship web connecting them. That structured context goes to the LLM alongside the vector chunks from Qdrant.
The graph is one retriever among five that run concurrently: documentation vector search (Qdrant) covering inventory and product data, product catalog search, data sources like human feedback and curated FAQs, the knowledge graph entity-relationship retriever, and chat history retrievers for channels like email, social, and tickets. All five run in parallel, results merge in priority order, and the unified context goes to the LLM, giving it better insights into the customer's actual question. This is the hybrid retrieval architecture we described in Beyond RAG: How We Rebuilt Our AI Around Planning.
Six Wins Vectors Can't Match
1. Entity Resolution. Normalized-name-plus-type deduplication collapses "Pro Plan," "Pro Subscription," and "the paid tier" into one node. Vector databases return three different chunks and hope the LLM figures it out. The graph knows they're the same entity from the start.
2. Multi-Hop Reasoning. "What policy covers refunds for the Pro Plan?" requires traversing Pro Plan → COVERED_BY → Refund Policy. Two hops. A vector database has to hope one chunk happens to mention both terms in the same passage. The graph traverses the explicit path.
3. Type Disambiguation. "Apple" as :ORGANIZATION:Entity and "Apple" as :PRODUCT:Entity stay separate even though their embeddings are near-identical. Node labels prevent the kind of cross-type confusion that plagues vector-only systems.
4. Relationship Strength Scoring. Every edge carries a 1-to-10 strength score. Retrieval can rank by how strongly entities are actually related, not just how semantically similar their descriptions happen to be. A product "requires" a specific accessory (strength 9) differently than it "is sometimes mentioned alongside" another product (strength 3).
5. Provenance. Every node carries the source document URLs it was extracted from, enabling answer visualization and audit trails. When the AI Shopping Assistant tells a customer that the Pro Plan includes priority support, it can point to the exact help article that fact came from. This is how Alhena delivers hallucination-free answers with verifiable citations.
For a deeper look at response-level tracing, see our guide on how Alhena traces every AI response back to its source.
6. Domain-Adaptive Schema. The config tuner auto-generates the entity and relationship taxonomy per customer. No hand-crafted ontology, no rigid NLP pipeline, no manual logic rules. No generic schema that forces your product catalog into predefined categories. A beauty brand's graph captures INGREDIENT → SAFE_FOR → SKIN_TYPE relationships. A home furnishing store's graph captures PRODUCT → FITS_IN → ROOM_TYPE. Each graph reflects the real structure of that business's data.
Why Hybrid Beats Either Alone
The knowledge graph handles precision: compatibility checks, policy lookups, multi-attribute queries where every constraint must be enforced. Vector search handles breadth: fuzzy conversational queries like "something cozy for fall evenings" where there's no exact catalog match.
Together, they cover the full range of what customers actually ask. Tatcha saw 3x conversion rates with this approach. Puffy, a customer service leader among DTC brands, reached 90% CSAT. These predictive analytics on conversion lift with 63% automated resolution. The accuracy of graph-grounded responses builds a better customer experience and the kind of trust that turns conversations into revenue.
The Unified Memory layer in Alhena’s AI ecosystem ties it all together, giving the AI a continuous understanding of each customer across every touchpoint, with the knowledge graph providing the structured product intelligence underneath.
Ready to see this architecture in action? Book a demo with Alhena AI or start for free with 25 conversations.
Knowledge Graph Use Cases Across E-Commerce Verticals
The use cases for knowledge graphs in digital commerce go well beyond simple product lookup. Here are the commerce platform scenarios where structured graph data consistently outperforms vector-only retrieval:
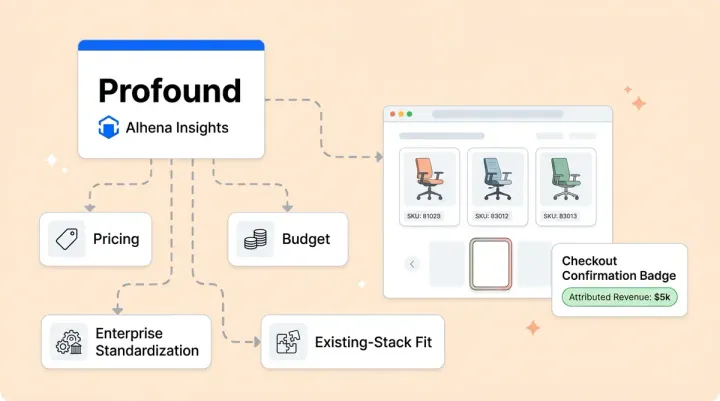
Product recommendations with constraints. A shopper asks for a gift under $50 that's safe for someone with nut allergies. Vector search returns semantically similar products. The knowledge graph enforces both the price constraint and the ingredient safety constraint simultaneously, then ranks recommendations by relationship strength. The result is AI-generated suggestions that are both relevant and verifiable.
Inventory management and availability. "Do you have this in size 8?" requires checking real-time inventory management data, not searching through product descriptions. The graph connects SKU nodes to inventory nodes with typed availability relationships, so the inference engine returns a definitive yes or no.
Cross-category discovery. A shopper looking at running shoes might also need moisture-wicking socks, a foam roller, and a hydration pack. The graph stores interconnected "complementary" relationships across categories, enabling recommendations that span your entire catalog rather than staying within a single product category.
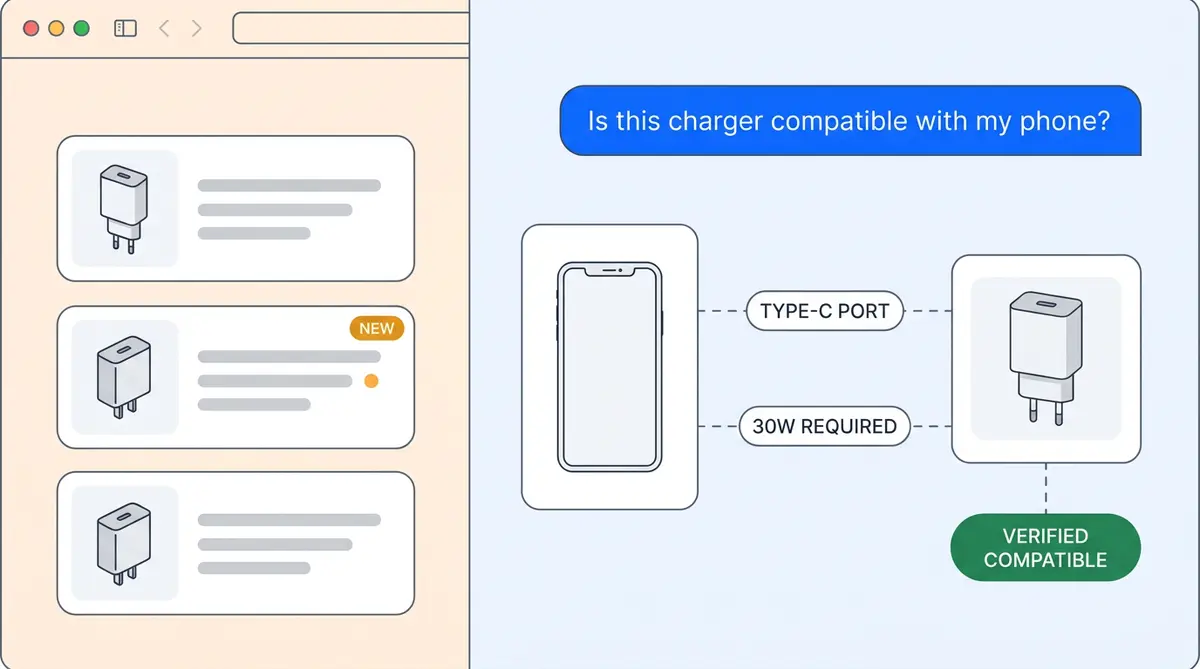
Predictive compatibility. For electronics, home furnishing, and automotive parts, compatibility isn't optional. The graph stores explicit "compatible_with" relationships between products, so when a customer asks "Will this filter fit my Dyson V15?", the answer comes from structured data, not from semantic similarity to product descriptions that happen to mention Dyson.
Building and Maintaining the Graph at Scale
Graph creation with large language models has made knowledge graphs practical for mid-market brands, not just enterprises with dedicated data science teams. Alhena's pipeline uses the OpenAI API for entity extraction, but the architecture supports any embedding model. The datasets flow through automated pipelines that handle deduplication, summarization, and relationship scoring without manual intervention.
Keeping the graph fresh matters just as much as building it. When you add new products, update policies, or change pricing, the graph needs to reflect those changes. Alhena's agentic chunking process segments updated data sources by semantic structure, re-extracts entities and relationships, and merges them into the existing graph. Deleted products get pruned. Updated attributes get overwritten. New relationships get scored and indexed.
This is fundamentally different from re-embedding your entire catalog into a vector database every time something changes. Graph updates are incremental and targeted, which means your AI agent always has current structured data without the cost and latency of full re-indexing.
How Knowledge Graphs Evolve With Your Business
The knowledge graph isn't a static artifact. It evolves as your product catalog grows, as customer behavior shifts, and as your commerce platform adds new categories and data sources. This is where the architecture pays dividends over time.
Traditional machine learning algorithms struggle with dynamic product catalogs because retraining takes time and compute. Vector databases need periodic full re-indexing. A knowledge graphs handle change incrementally: new items become new nodes with connections to existing categories. Updated pricing or inventory data overwrites specific edge properties without touching the rest of the graph.
For teams that use prompt engineering to fine-tune their AI's behavior, the graph provides a stable factual backbone. You can adjust how AI systems and the LLM format answers or handles edge cases through prompt tuning, while the graph ensures the underlying facts (compatibility, ingredients, sizing, availability) remain deterministic and verifiable. The AI-generated responses stay grounded regardless of how creative the prompt engineering gets.
Alhena's system also supports predictive analytics and predictive modeling on conversation patterns. The graph tracks which entity connections get queried most often, revealing which product recommendations drive the most conversions. These insights feed back into the graph, strengthening high-value connections and surfacing deeply interconnected products that shoppers frequently ask about together.
If you run custom internal tools connected via API key authentication, the knowledge graph integrates with those data sources through the same graph creation pipeline. Pricing databases, warehouse management systems and order management, and loyalty program data all become nodes in the graph, giving AI systems a unified view of your customer's context. You can visualize these connections in Alhena's dashboard to audit which data sources contribute to each answer.
The result is an AI assistant that doesn't just answer questions. It optimizes the answer quality and semantic search accuracy over time as the graph grows richer, as more datasets feed into it, and as the semantic search layer captures broader conversational patterns from your customers.
Knowledge Graph Ontology and the Logic Behind Smarter Recommendations
Every knowledge graph needs an ontology: a formal type system that defines what types of entities exist, what relationships connect them, and what logic governs those connections. In ecommerce, the schema determines whether your AI treats "running shoes" and "trail shoes" as siblings, parent-child categories, or entirely separate concepts. Getting the type system right is what separates a useful recommendation system from one that suggests ski boots to someone shopping for sandals.
Alhena's ontology is domain-adaptive. When the graph ingests a new commerce platform's catalog, the graph creation pipeline reads the product taxonomy and maps it to an existing ontology layer. If the platform uses flat categories, the pipeline infers hierarchy from product attributes and purchase histories. If it uses a deep taxonomy, the pipeline preserves that structured data as interconnected nodes. The ontology evolves as the catalog changes, so new product lines slot into the right place without manual remapping.
This type layer powers the inference engine. When a customer asks "what goes with this dress?", the system doesn't run a machine learning similarity search in isolation. It follows the graph's logic: the dress node connects to a "cocktail attire" category, which links to complementary categories like clutch bags and statement earrings. The inference walks these structured data paths, applies relationship strength scores, and returns AI-generated recommendations that make sense as a complete outfit. Traditional recommendation systems built on collaborative filtering and simpler recommendation systems miss this kind of reasoning because they operate on purchase correlation, not product logic.
The schema also governs how the graph handles cross-platform commerce use cases. Brands selling on multiple commerce platforms (Shopify, WooCommerce, Salesforce Commerce Cloud) often have inconsistent product taxonomies across channels. The knowledge graph normalizes these into a unified schema, so the LLM generates consistent AI-generated recommendations and answers regardless of which platform the buyer originally browsed. Machine learning models trained on this normalized graph data produce better predictions because the training signal isn't polluted by taxonomy mismatches across the ecosystem.
For visualization, Alhena's dashboard lets you explore the data model as an interactive graph. You can visualize how inference flows from a user query through graph nodes, relationship edges, and category hierarchies to the final answer. This transparency matters for debugging, for training customer service teams, and for auditing which data sources and logic paths influence AI-generated responses.
Knowledge Graph Databases vs Traditional AI Systems: Key Differences
Traditional AI systems in ecommerce rely on one of two approaches: keyword matching against a product database, or vector-based semantic search against chunked datasets. Both have limits. Keyword search can't handle natural language queries like "something warm for a ski trip under $200." Vector search handles the semantic part but loses structured data relationships between products, categories, and policies.
Knowledge graph databases solve this by storing nodes and edges as first-class objects. Every product, category, policy, and buyer interaction becomes a node with typed edges connecting them. The graph creation process extracts these objects from your catalog data, support documentation and tools, and purchase histories, then builds an interconnected web of structured data that AI systems can traverse at runtime.
The difference shows up in three use cases. First, when a buyer asks a question that requires inference across multiple data sources, graph databases follow connection paths to find the answer. Traditional AI systems would need to retrieve and stitch together separate text chunks and hope the LLM can piece together the logic. Second, for product recommendations, the knowledge graph walks category connections and product attributes to suggest items that are actually compatible, not just semantically similar. Third, for analytics and visualization, graph databases let you see exactly how entities connect: which products link to which categories, which policies apply to which plans, and which queries trigger which inference paths.
The commerce implications are significant. Brands running AI-generated product recommendations from a knowledge graph see higher conversion rates because the recommendations respect real constraints: compatibility, availability, price ranges, and seasonal relevance. Traditional recommendation systems built on vector similarity alone miss these structured connections. The knowledge graphs approach also makes AI-generated answers more auditable. Every response traces back to specific nodes, edges, and data sources in the graph, giving teams full transparency into why the LLM said what it said.
From Graph Data to Real-Time AI: The Full Stack
The real power of a knowledge graph in ecommerce AI systems comes from how graph data flows through the entire stack. It starts with graph creation: ingesting product catalogs, support documentation, and purchase histories into interconnected nodes and connections. The OpenAI API handles entity extraction and description summarization during this phase, turning unstructured datasets into structured data that Neo4j can store and query.
At inference time, the LLM traverses graph databases using Cypher queries to find answers that require multi-hop reasoning across interconnected nodes. A single user query might trigger inference across product attributes, category hierarchies, and policy documents. The knowledge graph returns structured results with full provenance, so every AI-generated response maps back to specific entities, relationships, and data sources.
For commerce teams, the analytics layer built on top of graph data reveals patterns that traditional AI systems miss. You can visualize which product recommendations drive the most conversions, track how customers navigate interconnected categories, and run predictive analytics on which product combinations sell best together. These insights feed back into the graph, making recommendation systems smarter with every interaction.
The semantic search layer works alongside the graph for queries that don't fit neatly into structured data paths. "Something cozy for fall" is a semantic search problem. "Does the Pro Plan include free returns?" is a graph traversal problem. Alhena's hybrid architecture handles both, using machine learning for semantic matching and graph logic for structured inference. This is what separates knowledge graph databases from simpler AI systems that treat every query the same way.
Whether you're running a commerce platform on Shopify, WooCommerce, or Salesforce Commerce Cloud, the knowledge graph adapts to your catalog's data model and evolves as your business grows. New products, new categories, new policies: each becomes a node in the ecosystem, connected to everything that came before. That's why brands that invest in graph creation see compounding returns on their AI investment over time.

Frequently Asked Questions
What is the difference between a knowledge graph and a vector database for commerce AI?
A vector database converts text into numerical embeddings and finds semantically similar content. A knowledge graph stores entities (products, policies, features) and the typed relationships between them. For e-commerce, vector search handles fuzzy queries well but can't traverse structured relationships like "which policy governs refunds for this plan" or "which accessories are compatible with this product." Alhena uses both: Neo4j for structured graph queries and Qdrant for vector similarity search, merged at query time.
How does Alhena build a knowledge graph from my product data?
Alhena’s graph creation runs a six-stage pipeline: (1) domain-adaptive config tuning that auto-generates entity types and relationship patterns for your specific business, (2) isolated database creation per customer, (3) entity and relationship extraction via GPT-4o Mini with deduplication, (4) description summarization across multiple sources, (5) embedding generation for every node and edge, and (6) vector index creation inside Neo4j. The entire process is automated and tailored per customer domain.
How does the knowledge graph prevent AI hallucinations?
Every entity node carries the source document URLs it was extracted from, providing full provenance. When the AI answers a question, it traces the answer through explicit graph relationships rather than relying on text similarity. Entities are deduplicated by normalized name and type, so "Pro Plan" and "Pro subscription" resolve to one node with one verified description. This structural grounding eliminates the ambiguity that causes hallucinations in vector-only systems.
What is multi-hop reasoning and why does it matter for e-commerce?
Multi-hop reasoning means traversing multiple relationships to answer a question. "Can I get a refund if I downgrade from the Pro Plan?" requires two hops: Pro Plan → GOVERNED_BY → Refund Policy → APPLIES_TO → Downgrade. A vector database has to hope one text chunk mentions all three concepts together. The knowledge graph traverses the explicit path and returns a definitive answer. E-commerce queries frequently involve multiple entities (products, policies, compatibility, sizing), making multi-hop reasoning essential.
Does Alhena use a custom schema for each customer's knowledge graph?
Yes. Before extracting any entities, Alhena's config tuner samples your training data and auto-generates the entity types and relationship patterns that make sense for your domain. A beauty brand's graph captures INGREDIENT → SAFE_FOR → SKIN_TYPE relationships. A home furnishing store's graph captures PRODUCT → FITS_IN → ROOM_TYPE. The schema is never hardcoded or one-size-fits-all.
How does the hybrid retrieval system work at query time?
Five retrievers run concurrently: documentation vector search (Qdrant), product catalog search, human feedback and curated FAQs, the knowledge graph entity-relationship retriever, and chat history retrievers. Results are merged in priority order and the unified context goes to the LLM. The graph adds structured entity and relationship data that the vector hits alone don't have, while vector search covers fuzzy, conversational queries.
What does relationship strength scoring do?
Every edge in Alhena's knowledge graph carries a strength score from 1 to 10, quantifying how tight the connection between two entities is. A product that "requires" a specific accessory might score 9, while a product "sometimes mentioned alongside" another scores 3. This lets retrieval rank by actual relationship strength, not just embedding similarity, which produces more accurate and relevant answers.
How long does it take to deploy Alhena's knowledge graph?
Alhena deploys in under 48 hours with no developer resources required. The platform connects to your e-commerce platform (Shopify, WooCommerce, Magento, Salesforce Commerce Cloud), ingests your product catalog and knowledge sources, and automatically builds the knowledge graph through its six-stage pipeline. Each customer gets an isolated, versioned Neo4j database that can be rebuilt without downtime.