The Black Box Problem in E-Commerce AI
In 2024, Air Canada's chatbot told a grieving customer he could apply for bereavement fares retroactively. That was false. A tribunal ruled the airline liable for roughly $812 CAD in damages, setting a legal precedent: companies are responsible for what their AI says, whether the information is accurate or not.
That case wasn't unusual. According to Hyperleap AI, 39% of AI-powered customer service bots were pulled back or reworked in 2024 because of hallucinated responses and related errors. Enterprises spend an average of $1.3 million annually on rework caused by AI-generated inaccuracies, per Spotlight.ai.
The root cause isn't that AI models are bad. It's that most e-commerce teams have no way to see why the AI said what it said. The response arrives, the customer reads it, and if the output is wrong, nobody knows until a complaint shows up. That's the black box problem, and it's one that generative AI has made worse, not better.
Alhena's Conversation Debugger was built to eliminate it. Every AI response is traceable back to the exact product data, knowledge base article, or policy document that grounded it. This post walks through how it works, layer by layer.
What "Hallucination-Free" Actually Requires
The term "hallucination-free" gets tossed around a lot. Most AI platforms use it to mean "we use RAG." But retrieval-augmented generation (RAG) alone doesn't solve the problem. A Suprmind benchmark study found that even with RAG, domain-specific hallucination rates in RAG systems still land between 10% and 20% in production environments.
Here's why. RAG retrieves documents, but the LLM can still misinterpret them or lose context. It can blend two correct facts into one incorrect answer. A return policy says "30 days for electronics" and a warranty document says "90 days for manufacturer defects." The AI synthesizes these into "90-day returns on electronics," which is confidently wrong despite both source documents being accurate.
True hallucination-free AI requires more than retrieval. It requires a verification foundation at every step: Did the system retrieve the right document? Did it interpret the content correctly? Can every claim in the response be mapped back to a specific source? That's where ai hallucination detection moves from buzzword to architecture.
How Alhena's Conversation Debugger Works
The Conversation Debugger isn't a single feature. It's a three-layer system that runs on every AI response Alhena generates, across every channel: web chat, email, Instagram DMs, WhatsApp, and voice.
Layer 1: Real-Time Source Tracing
Through real-time monitoring, as the AI generates a response, Alhena's system monitors which knowledge sources it pulls from. If the AI can't trace an answer back to a verified citation from relevant sources and approved materials, it doesn't guess. It either escalates to a human agent or tells the customer it doesn't have that information.
Approved materials include product catalogs, FAQ documents, help desk history, and policy documents. Anything outside these verified, trusted sources triggers automatic detection. This is fundamentally different from general-purpose LLM systems that pull from broad training data and hope for the best.
Layer 2: Automated Flagging and Confidence Scoring
Not every response needs human review. Alhena's second layer validates AI outputs using three mechanisms to surface the conversations that do:
- Low-confidence classifier scores that fall below category-specific thresholds
- Negative customer satisfaction ratings that indicate something went wrong
- Escalation triggers for off-topic questions, malicious prompts and injection attempts, or safety-sensitive topics
This monitoring system flags less than 1% of conversations. That's the signal-to-noise ratio you want: enough to catch real problems without drowning your team in false alarms.
Layer 3: Pattern-Level Analysis
Individual errors matter, but patterns matter more. Alhena samples 2% to 5% of conversations weekly to identify systemic issues: recurring low-confidence categories, persistent knowledge base gaps, or outdated references that keep generating incorrect answers.
This is where debugging shifts from reactive detection to proactive prevention. Instead of waiting for customer complaints, your team spots problems before they compound.
Inside a Debugging Session: What Your Team Actually Sees
When a conversation gets flagged, the review screen shows everything your team needs to understand what happened and why.
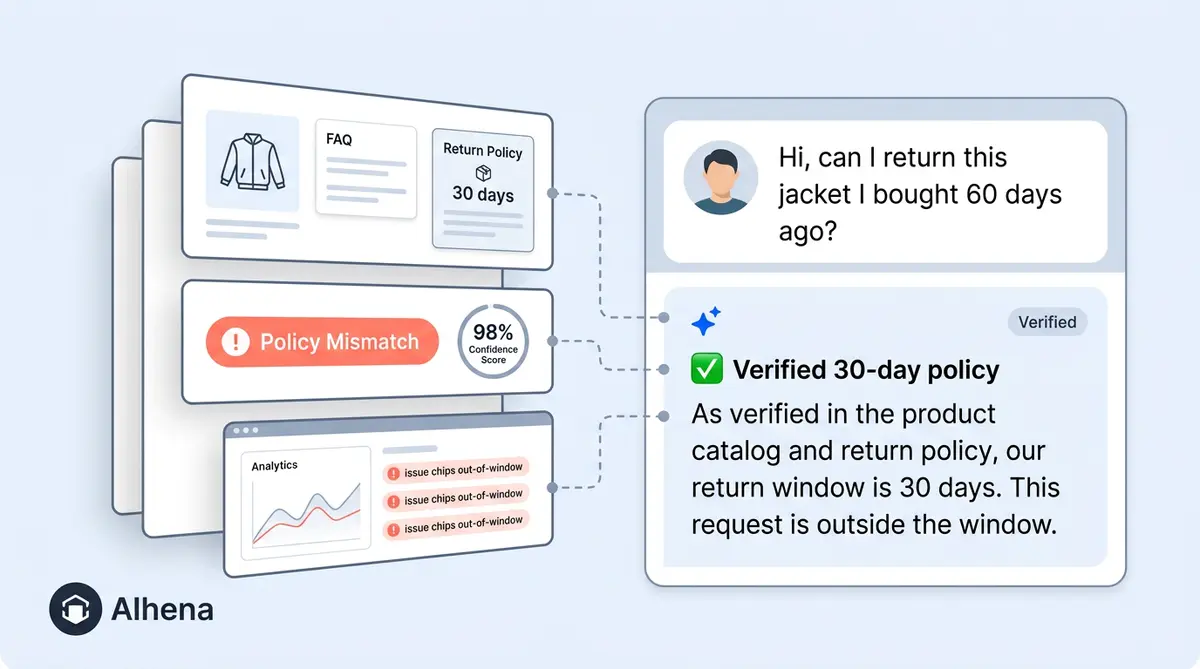
Say a customer on your Shopify store asks, "Can I return this jacket after 45 days?" Your return policy is 30 days. The AI correctly says no, but the customer pushes back, claiming "the website says 60 days." The AI holds firm. The customer leaves a negative satisfaction rating, and the conversation gets flagged.
Your team opens the Conversation Debugger and sees:
- The complete conversation with the original customer prompts and AI responses
- The specific knowledge sources the AI referenced: in this case, the return policy document stating "30-day return window for all apparel"
- The reasoning chain explaining why the AI selected that source and how it formulated the response
- Confidence alignment metrics showing the AI's certainty level and whether it matched the threshold for that category
- Source-detection status confirming whether every claim in the response traced back to verified content
In this case, the AI was right. The customer was confused. Your team closes the flag, and the negative rating doesn't skew your analytics. But if the AI had been wrong, the debugger would show exactly where the reasoning broke down: which source it misinterpreted or which document was outdated.
Why Confidence Scores Alone Aren't Enough
Most AI platforms, including Zendesk AI and Intercom Fin, offer some form of confidence scoring. Zendesk provides "AI reasoning controls" with confidence scores for intent and sentiment predictions. Intercom runs a multi-step validation process and reports a 72% accuracy rate with a 6% hallucination rate, per their own documentation.
But confidence scores answer a different question. They tell you how sure the model is. They don't tell you why it gave a specific answer or which source document it pulled from. Without context about which document grounded each claim, a model can be 95% confident and still be wrong, especially when it synthesizes multiple documents into a single response.
Gorgias takes a different approach with dual-model validation: one model generates, a second model validates before sending. But the quality control is binary. Either send or escalate. There's no trace-level insight into which source documents grounded each response.
AI chatbot quality assurance at scale needs more than a confidence number. It needs a full audit trail that maps every claim to its source with clear citations and evidence. That foundational gap is what separates "our AI is accurate" and "here's proof."
The Regulatory Clock Is Ticking
The EU AI Act's transparency obligations under Article 50 take full effect in August 2026. Companies deploying customer-facing AI chatbots must ensure humans know they're interacting with a machine, and AI-generated content must be identifiable.
While the current rules focus on disclosure, the direction is clear. Gartner predicts that by 2028, 50% of GenAI deployments will invest in explainability and LLM observability, up from just 15% today. The priority is shifting from speed metrics to "deeper quality measures such as factual accuracy, logical correctness, and sycophancy."
For e-commerce brands, this means LLM traceability isn't a nice-to-have. It's the audit infrastructure you'll need when regulators or legal teams ask, "How did your AI arrive at that answer?" Companies building AI transparency now will be ahead of the compliance curve.
From Debugging to Prevention: How the Feedback Loop Works
Finding errors is only half the job. The Conversation Debugger feeds directly into Alhena's corrective workflow, turning every flagged conversation into a system improvement.
When a team reviews a flagged response, they can take four actions:
- Add new FAQ entries to cover gaps the AI couldn't answer
- Update behavioral guidelines to adjust how the AI handles similar queries
- Flag knowledge gaps for your content team to fill with updated product information
- Adjust confidence thresholds to fine-tune when the AI escalates vs. responds
These corrections propagate across all channels within minutes. If your team updates a return policy clarification in the debugger, that fix applies to web chat, email, social DMs, WhatsApp, and voice simultaneously. There's no channel-by-channel patching.
This is what separates Alhena from developer-focused observability systems like LangSmith or Arize. Those platforms are built for engineers debugging prompt chains and LLM retrieval pipelines. Alhena's Agent Assist and Conversation Debugger are built for CX managers and e-commerce teams who need to understand and fix AI behavior without writing code.
Over time, the pattern-level analysis identifies which product categories generate the most flagged responses, which knowledge base articles need updates, and where your AI's accuracy improves or degrades. Brands like Tatcha have used this kind of continuous tuning to achieve 3x conversion rates and 82% chat deflection. Crocus reached an 86% deflection rate with 84% CSAT.
What This Means for Your Team
The Conversation Debugger changes the relationship between your team and your AI. Instead of a black box that either works or doesn't, you get a trusted, transparent system where every response has a provable source.
For CX managers, it means you can audit any conversation in seconds and know exactly why the AI said what it said. No guessing, no recreating scenarios.
For e-commerce directors, it means ai chatbot accuracy becomes measurable. You can track grounding rates, flag trends, and tie AI performance directly to business outcomes through Alhena's revenue attribution analytics.
For compliance teams, it means you have the audit trail regulators will increasingly demand. Every response, every source, every reasoning chain: logged and reviewable.
And for customers, it means the AI they interact with on your Shopify, WooCommerce, or Salesforce Commerce Cloud store gives answers that are credible and trustworthy. Not because the AI promises accuracy, but because your team can verify it.
The AI customer service market is projected to grow from $12 billion to nearly $48 billion by 2030. As AI handles more customer interactions, the question isn't whether you need hallucination detection. It's whether your current tools can show you exactly where an answer came from.
Ready to see how the Conversation Debugger works with your product data? Book a demo with Alhena AI or start free with 25 conversations.

Frequently Asked Questions
What is the Conversation Debugger in Alhena AI?
The Conversation Debugger is a three-layer system that traces every AI response back to its verified source data. It provides real-time source tracing, automated flagging of low-confidence responses, and pattern-level analysis across 2-5% of weekly conversations. CX teams can see the exact product catalog entry, FAQ, or policy document that grounded each answer.
How does Alhena detect AI hallucinations in ecommerce chatbots?
Alhena uses a multi-checkpoint approach. Layer 1 monitors source tracing in real time, blocking any output that can't be mapped to verified content. Layer 2 flags conversations with low-confidence scores, negative CSAT ratings, or escalation triggers. Layer 3 samples conversations weekly to catch systemic patterns. Less than 1% of conversations get flagged, keeping the signal-to-noise ratio high.
How is Alhena's approach different from Zendesk AI or Intercom Fin?
Zendesk AI offers confidence scores for intent and sentiment but doesn't provide per-response source tracing. Intercom Fin uses multi-step validation with a reported 72% accuracy and 6% hallucination rate, but has no merchant-facing debugger. Alhena's Conversation Debugger gives CX teams full visibility into which source documents grounded each response, plus a corrective workflow to fix issues across all channels within minutes.
Can the Conversation Debugger help with EU AI Act compliance?
Yes. The EU AI Act's Article 50 transparency obligations take full effect in August 2026. Alhena's Conversation Debugger creates an audit trail for every AI response, logging the sources referenced, reasoning chains, and confidence metrics. This gives compliance teams the documentation and governance records they need to demonstrate how the AI arrived at each answer.
Does Alhena's hallucination detection work across all channels?
Yes. The Conversation Debugger runs on every response across web chat, email, Instagram DMs, WhatsApp, and voice. When corrections are made through the debugger, they propagate to all channels within minutes. There's no need to patch each channel separately.
What happens when the Conversation Debugger flags a response?
Flagged conversations show the complete customer interaction, the specific knowledge sources referenced, the AI's reasoning chain, and confidence alignment metrics. Review teams can then add FAQ entries, update behavioral guidelines, flag knowledge gaps for content teams, or adjust confidence thresholds. Fixes apply system-wide in minutes.
How much does AI hallucination cost ecommerce brands?
Enterprises spend an average of .3 million annually on rework from AI-generated inaccuracies, according to Spotlight.ai. In 2024, 39% of AI-powered customer service bots were pulled back due to hallucinated content. Beyond direct costs, 32% of customers leave after a single bad experience, making hallucination a revenue and retention problem.
How long does it take to set up the Conversation Debugger?
The Conversation Debugger is included in every Alhena AI deployment. Alhena systems deploy in under 48 hours with no developer resources needed. Once your product catalog, FAQs, and policy documents are connected, the three-layer quality control system activates automatically across all channels.