Agentic Chunking or Smart Chunking improves context preservation in Retrieval Augmented Generation.
Introduction
Generating accurate and complete answers using Large Language Models (LLMs) depends on two main factors:
1. The quality of the LLM.
2. The quality of the context provided to the LLM.
In this post, we’ll focus on the second factor—how to prepare documents to provide high-quality context. This involves processing, chunking, embedding, and retrieving documents using semantic search. One key part of this is chunking, or breaking down documents into smaller, manageable pieces.
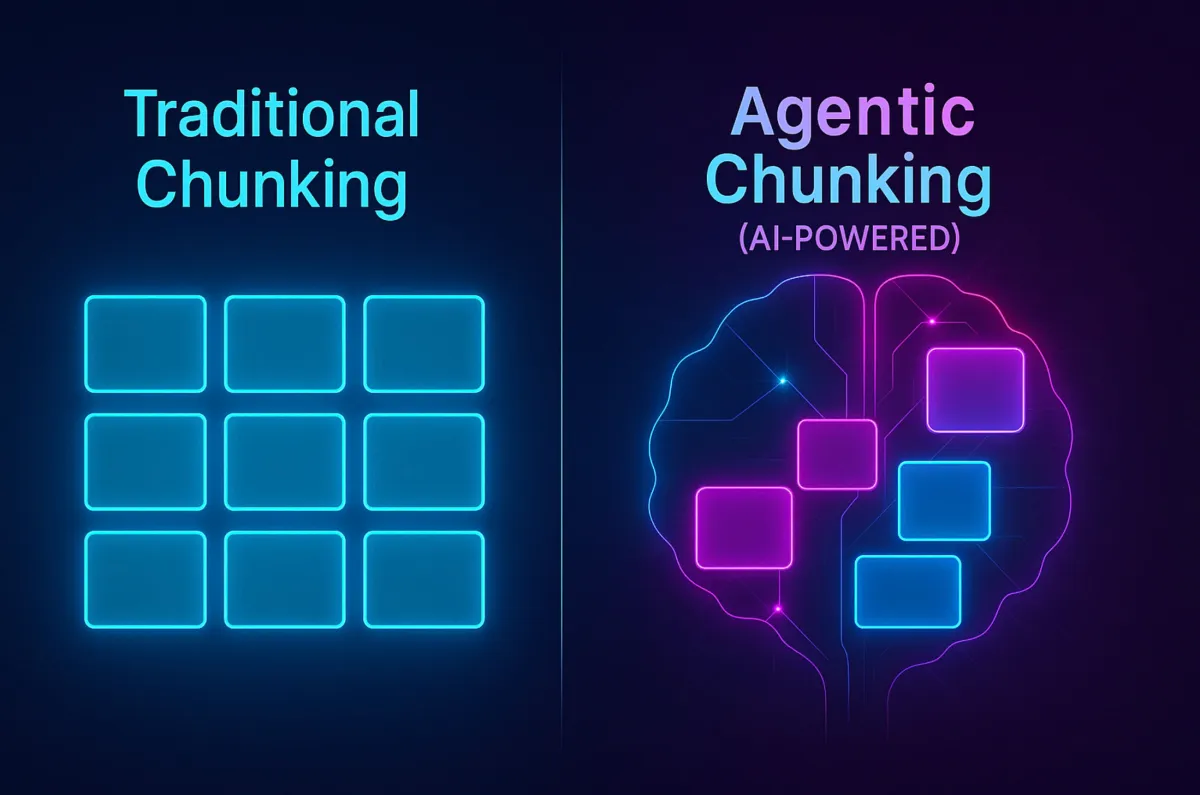
Traditional chunking methods often fall short, losing context and leading to incomplete answers. We’ll quickly go over the limitations of these old methods and introduce a new approach: Agentic Chunking. This method leverages LLMs to create context-rich, meaningful chunks, resulting in more accurate and complete responses.
What Is Agentic Chunking?
Agentic chunking is a document segmentation technique that uses a large language model to split text into semantically coherent chunks. Unlike fixed-size or rule-based methods, it applies AI reasoning to decide where one topic ends and another begins, much like a human editor would break a document into logical sections.
The term "agentic" refers to the autonomous, decision-making behavior of the LLM during the splitting process. The model reads through the text, identifies thematic boundaries, and groups related sentences together. Each resulting chunk captures a complete idea or concept rather than an arbitrary slice of characters.
This matters for RAG (Retrieval Augmented Generation) systems because retrieval quality depends on chunk quality. When a user asks a question, the system searches a vector database for the most relevant chunks. If those chunks contain fragmented or mixed topics, the LLM receives confusing context and produces incomplete or inaccurate answers. Agentic chunking solves this by ensuring each chunk is self-contained and topically focused.
Traditional Chunking Methods and their limitations
| Method | Description | Limitations |
|---|---|---|
| Fixed-Size Character Chunking | Divides text into fixed-size chunks with overlaps. | - Cuts off sentences/words, losing meaning. - Ignores document structure (headings, lists). - Arbitrary breaks mix unrelated topics, disrupting flow. |
| Recursive Text Splitting | Splits text by hierarchical separators (paragraphs, sentences, words). | - Overlooks complex structures (headers, tables). - Cuts off paragraphs, bullet points mid-way - Doesn't take semantic meaning into account |
| Semantic Chunking | Groups sentences based on embedding similarity to create context-aware chunks. | - Coherence issues when sentences within a paragraph differ semantically. - Computationally intensive, especially with large documents. |
Note: After trying several "state-of-the-art" chunking solutions in the market, we, at Alhena, found them unsatisfactory. This led us to develop our in-house solution: Agentic Chunking.
Introducing Agentic Chunking (aka Smart Chunking)
Agentic Chunking is an LLM-based approach that simulates human judgment in text segmentation to create semantically coherent chunks. It overcomes the limitations of traditional methods by intelligently grouping textual elements based on meaning and context.
Key Steps in Agentic Chunking
- Mini-Chunk Creation: The document is initially split into mini-chunks (e.g., ~300 characters each) using Recursive Text Splitting. This ensures that mini-chunks do not cut off sentences
- Marking Mini-Chunks: Each mini-chunk is annotated with unique markers to aid the LLM in recognizing chunk divisions. LLMs cannot count characters precisely but can recognize patterns.
- LLM-Assisted Chunk Grouping:
- The annotated document is provided to an LLM along with specific instructions.
- The LLM is tasked with analyzing the sequence of mini-chunks and grouping them into larger, semantically coherent chunks.
- Constraints, such as a maximum number of mini-chunks per chunk, are imposed.
- Chunk Assembly: The final chunks are formed by combining the mini-chunks selected by the LLM. Attach relevant metadata to each chunk, such as source information and chunk indices.
- Chunk Overlap for Context Preservation: Include the previous and/or next mini-chunk when forming each chunk to create overlapping between chunks.
- Guardrails and Fallback Mechanisms
- Chunk Size Limits: Enforce maximum chunk sizes to stay within LLM input constraints.
- Context Window Management: For documents exceeding the LLM's context window, split and process them in manageable parts.
- Validation: Verify that all mini-chunks are included.
- Fallback to Recursive Splitting: If LLM processing fails or is unavailable, default to using recursive text splitting.
- Parallel Processing: Utilize multi-threading for faster processing.
Benefits of Agentic Chunking
- Semantic Coherence: Generates semantically meaningful chunks, enhancing the relevance and accuracy of retrieved information.
- Context Preservation: Maintains the flow within chunks, enabling LLMs to produce more accurate and contextually appropriate responses.
- Flexibility: Adapts to documents of varying lengths, structures, and content types, making it suitable for diverse applications.
- Robustness: Features guardrails and fallback mechanisms to ensure consistent performance, even with unexpected document structures or LLM limitations.
- Adaptability: Integrates seamlessly with different LLMs and can be fine-tuned in-house to create coherent chunks.
Agentic Chunking vs Semantic Chunking
Semantic chunking and agentic chunking both aim to produce meaningful text segments, but they work in fundamentally different ways. Semantic chunking uses an embedding model to measure similarity between consecutive sentences. When the cosine distance between two adjacent sentences crosses a threshold, it creates a split. The process is automated and statistical.
Agentic chunking takes a different approach. Instead of measuring similarity scores, it gives the full text to an LLM and asks it to identify logical groupings. The LLM understands context, argument flow, and document structure in ways that embedding-based similarity cannot. It can recognize that a paragraph introducing a concept and a paragraph three sentences later providing an example of that concept belong together, even if their surface-level embeddings differ.
Agentic Chunking vs Semantic Chunking: Key Differences
| Dimension | Agentic Chunking | Semantic Chunking |
|---|---|---|
| How it splits | LLM reads text and decides boundaries based on meaning | Embedding similarity scores detect topic shifts between sentences |
| Intelligence | Full reasoning: understands context, intent, document structure | Statistical: measures cosine distance between sentence embeddings |
| Chunk quality | Complete concepts with preserved context | Topically grouped but may split mid-argument |
| Adaptability | Can apply different strategies per section (tables, lists, prose) | Single approach applied uniformly across all content |
| Cost | Higher (requires LLM inference per document) | Moderate (embedding model inference only) |
| Speed | Slower (LLM processing time) | Faster than agentic, slower than fixed-size |
| Best for | Complex docs: legal, medical, multi-topic product catalogs | Simpler content with clear topic transitions |
| RAG accuracy | Highest (complete, self-contained chunks) | Good, but may miss cross-paragraph relationships |
The trade-off is clear: agentic chunking produces better chunks at higher cost and slower speed. For high-value use cases where answer accuracy matters more than processing speed (e-commerce product catalogs, legal documents, medical literature), agentic chunking is worth the investment. For simpler content or cost-sensitive pipelines, semantic chunking remains a solid middle ground between fixed-size splitting and full agentic processing.
Results
Implementing Agentic Chunking has significantly improved the completeness and accuracy of answers generated by Retrieval Augmented Generation (RAG) systems:
- 92% Reduction in Incorrect Assumptions: Previously, improper chunking led to AI making incorrect assumptions by chopping concepts midway, resulting in inaccurate customer responses. Agentic Chunking reduced these errors by 92%, greatly enhancing reliability.
- Improved Answer Completeness: Incomplete answers were common, especially for lengthy tutorials or guides. Agentic Chunking ensures comprehensive answers remain intact, providing more complete and satisfactory responses to users.
Agentic Chunking Performance Benchmarks
The table below shows how agentic chunking compares to other strategies across key metrics. These results come from Alhena's internal testing on e-commerce product documentation, where answer quality directly affects customer experience and conversion rates.
Chunking Strategy Performance Comparison
| Metric | Fixed-Size (512 tokens) | Recursive Splitting | Semantic Chunking | Agentic Chunking |
|---|---|---|---|---|
| Answer completeness | Low | Moderate | Good | Highest |
| Incorrect assumptions | Baseline | -30% | -50% | -92% (Alhena) |
| Context preservation | Poor (mid-sentence cuts) | Fair (paragraph boundaries) | Good (topic clusters) | Excellent (complete concepts) |
| Processing speed | Fastest | Fast | Moderate | Slower (LLM inference) |
| Handles complex docs | No | Partially | Partially | Yes (tables, lists, mixed formats) |
| Cost per 1M tokens | ~$0 (rule-based) | ~$0 (rule-based) | ~$0.02 (embedding only) | ~$0.50-2.00 (LLM calls) |
Benchmarks based on Alhena AI internal testing across e-commerce product documentation. "Incorrect assumptions" reduction measured against fixed-size baseline.
The cost trade-off is real, but context matters. For a customer-facing AI shopping assistant handling thousands of queries per day, the cost of agentic chunking during the one-time indexing phase is negligible compared to the revenue impact of better answers. Alhena's AI Shopping Assistant uses agentic chunking at ingestion time, so the higher processing cost is a one-time investment that pays dividends across every customer conversation.
Stay tuned for our next engineering blog post, where we'll dive deeper into how Agentic Chunking serves as a foundational approach in building knowledge graphs to support graph-based Retrieval-Augmented Generation (Graph RAG) and how it improves upon traditional RAG methods.
Implementing Agentic Chunking with LangChain and LlamaIndex
Both LangChain and LlamaIndex provide building blocks for agentic chunking, though neither offers a turnkey agentic chunker out of the box. Here's how teams typically approach it with each framework.
LangChain Approach
LangChain's agentic chunking workflow combines its text splitting utilities with LLM calls. The typical pattern involves three steps:
- Initial splitting: Use RecursiveCharacterTextSplitter to create small mini-chunks (200-300 characters). These serve as atomic units for the LLM to evaluate.
- LLM-based grouping: Pass mini-chunks to an LLM (via ChatPromptTemplate and SystemMessage) with instructions to group them by semantic coherence. The prompt asks the model to decide which mini-chunks belong together.
- Reassembly: Combine grouped mini-chunks into final chunks, add metadata (titles, summaries), and store them as Document objects in a vector database like Chroma or Pinecone.
IBM's tutorial on agentic chunking with LangChain demonstrates this pattern using WatsonxLLM and HuggingFaceEmbeddings. The key LangChain classes involved are RecursiveCharacterTextSplitter, ChatPromptTemplate, and Chroma for vector storage.
LlamaIndex Approach
LlamaIndex's node parsing framework provides a slightly different path. Its SemanticSplitterNodeParser handles embedding-based chunking natively, and you can layer agentic behavior on top by using an LLM to post-process and merge nodes based on topical coherence.
Why Most Teams Choose a Managed Solution
Building agentic chunking from scratch with LangChain or LlamaIndex requires ongoing maintenance: prompt tuning, handling edge cases (tables, nested lists, code blocks), adding guardrails for chunk size limits, and managing LLM costs at scale. This is why many production RAG systems use managed solutions that handle these complexities internally.
At Alhena, our AI training pipeline handles agentic chunking as part of a fully managed ingestion process. You upload your product data, and our pipeline handles chunking, embedding, and indexing automatically, with no LangChain or LlamaIndex setup required.
Build vs. Buy: Implementing Agentic Chunking
While Agentic Chunking is a small component, it plays a crucial role in the AI agent pipeline by producing semantically coherent chunks that enhance answer accuracy and completeness. Here's a look at the pros and cons of building it in-house versus leveraging expert solutions. To learn how we combined chunking improvements with a broader plan-execute-verify architecture that moves beyond RAG, see our detailed technical walkthrough.
Pros of Building In-House
- Control and Customization: Tailor the solution specifically to your use case, designing prompts and algorithms that align perfectly with your needs.
- Specificity: Develop chunking strategies uniquely suited to your data and applications.
Cons of Building In-House
- High Engineering Costs: Requires significant technical expertise and a substantial time investment, leading to increased costs.
- Unpredictable LLM Behavior: Predicting how large language models behave can be challenging. Building solely for your use case may not reveal all potential failures.
- Maintenance Overhead: Ongoing maintenance is needed as generative AI evolves rapidly.
- Production Challenges: Achieving prototype-level accuracy is one thing; making it production-ready with high accuracy (99%+) is a significant challenge requiring substantial effort.
Leave It to the Experts
To see how chunking fits into the complete pipeline from crawl to serve, read our full training pipeline walkthrough.
At Alhena, we are leading the industry in transforming the customer support using an Agentic AI architecture.
Implementing Agentic Chunking effectively demands expertise and resources. Instead of building it from scratch, consider leveraging solutions from experts like Alhena.
- Learn More: Alhena AI Products
- Create and Test Your Own AI Agent for Free: Sign Up
- Read Customer Success Stories: Customer Success stories

Alhena AI
Frequently Asked Questions
What is agentic chunking in AI?
Agentic chunking is a text segmentation method that uses a large language model to split documents into semantically coherent chunks. Instead of cutting text at fixed character counts or sentence boundaries, the LLM reads the content and decides where logical topic boundaries exist, producing chunks that capture complete ideas.
How does agentic chunking differ from semantic chunking?
Semantic chunking uses embedding similarity scores to detect topic shifts between adjacent sentences. Agentic chunking goes further by having an LLM reason about the full document structure, context, and argument flow. This produces higher-quality chunks but costs more due to LLM inference requirements.
How do you implement agentic chunking with LangChain?
The typical LangChain approach involves three steps: first split text into mini-chunks using RecursiveCharacterTextSplitter, then pass those mini-chunks to an LLM via ChatPromptTemplate to group them by semantic coherence, and finally reassemble grouped chunks with metadata into Document objects for vector storage in Chroma or Pinecone.
Is agentic chunking worth the higher cost?
For high-value use cases where answer accuracy directly impacts business outcomes (e-commerce, legal, medical), yes. Alhena's testing shows a 92% reduction in incorrect assumptions compared to fixed-size chunking. The cost is incurred once at ingestion time, while the quality improvement benefits every subsequent query.
What are the best chunking strategies for RAG in 2026?
The top strategies in 2026 are agentic chunking (highest quality, highest cost), semantic chunking (good balance of quality and speed), and recursive splitting at 512 tokens (fastest, decent quality). Newer approaches like contextual retrieval and late chunking complement these by adding context at retrieval time rather than chunking time.
Does agentic chunking work with LlamaIndex?
Yes. LlamaIndex's SemanticSplitterNodeParser handles embedding-based chunking natively, and you can layer agentic behavior by using an LLM to post-process and merge nodes based on topical coherence. However, LlamaIndex does not provide a built-in agentic chunker, so you need to build the LLM reasoning layer yourself.
How does Alhena AI use agentic chunking?
Alhena uses agentic chunking as part of its managed AI training pipeline. When you upload product data, the system automatically splits documents using LLM-based reasoning, adds metadata enrichment, and indexes chunks for retrieval. This produces hallucination-free answers for the AI Shopping Assistant without any manual chunking configuration.
What types of documents benefit most from agentic chunking?
Complex documents with mixed content types benefit most: product catalogs with specifications and descriptions, legal contracts with interdependent clauses, medical literature with referenced findings, and technical documentation with code examples. Simple, linear content like blog posts may not justify the additional cost.