The Confidence Paradox: AI Is Most Certain When It's Wrong
A 2026 MIT study found something unsettling in early 2026: large language models are 34% more likely to use confident language when generating incorrect information. Words like "definitely," "certainly," and "without doubt" appear more often in hallucinated responses than in accurate ones.
That single finding breaks the most common ecommerce assumption behind ecommerce AI chatbot systems. Ecommerce businesses assume that if the chatbot sounds confident, the answer is probably right. The opposite is closer to the truth.
OpenAI's own research explains why. Binary evaluation metrics reward guessing over expressing doubt. Under 0-1 scoring, saying "I don't know" always scores lower than a confident wrong answer. The training process and prompt tuning create an incentive to hallucinate. And Forrester predicts at least two major brand scandals from AI-generated misinformation in 2026, with Gartner forecasting "death by AI" legal claims exceeding 2,000 by year-end.
This is why e-commerce uncertainty thresholds exist. Not to limit your AI, but to make its accuracy and reliability measurable, protecting both sales conversions and revenue and its failures predictable. This article covers how faithfulness scoring works, what customers actually see at different e-commerce confidence levels, and how to calibrate the line between helpful and harmful for your specific e-commerce vertical.
How Faithfulness Scoring Makes Hallucination Risk Measurable
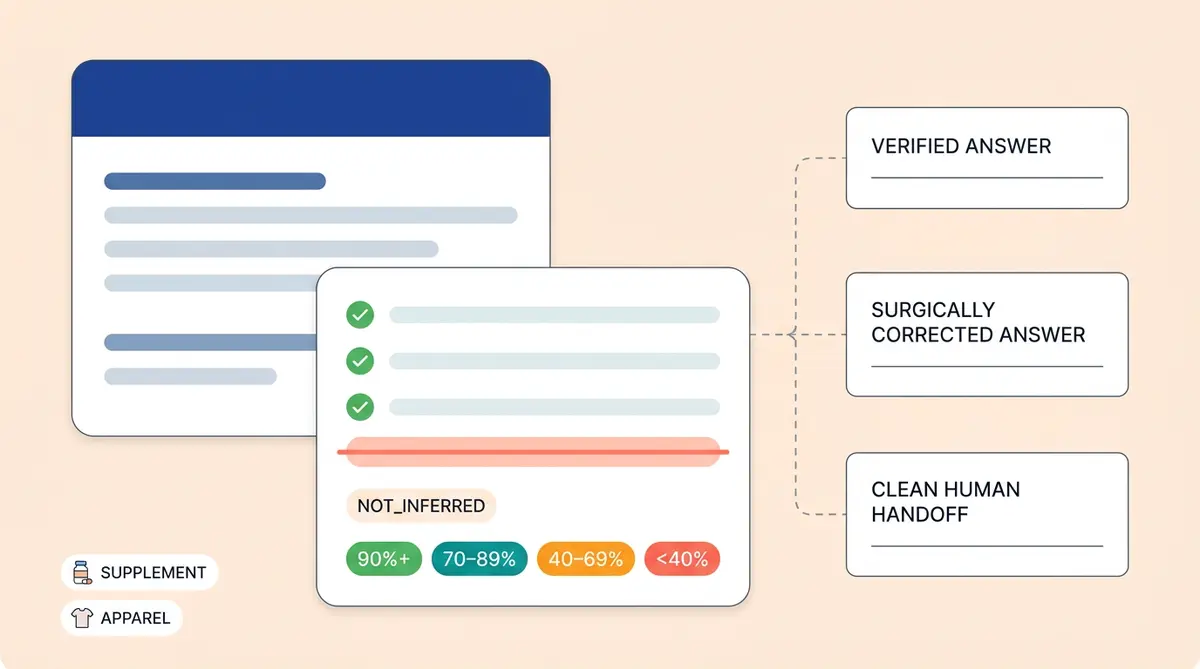
In ecommerce, a faithfulness score reduces hallucination risk to a number you can track per response. The formula is: validated facts divided by total facts, multiplied by 100%. If the AI's response contains five claims and four of them trace back to verified source data, the faithfulness score is 80%.
The system doesn't judge whether the response is true in the world. It judges whether the response is faithful to the retrieved data and context. That's a more tractable ecommerce problem. An external validation layer checks each claim against the RAG context the LLM actually received, all function and tool call outputs, the full chat history, and the user's query. If a fact isn't anchored to one of those sources, it's a hallucination, regardless of whether it happens to be true.
Alhena's pipeline runs two stages on every response. First, a FactsExtractor LLM reads the response and enumerates every unique factual statement (no validation yet, just extraction). Then a FactValidator independently checks each fact against the context and assigns one of three labels: DIRECTLY_INFERRED (explicitly stated), INDIRECTLY_INFERRED (logically derivable), or NOT_INFERRED (unsupported, a hallucination). Each validation includes a reasoning field for ecommerce auditing so it's auditable.
For e-commerce, this produces a numeric faithfulness score per response that is comparable across models, prompts, and bot profiles. Instead of sampling 1-5% of conversations after the fact, you can filter every response by its score and know exactly where accuracy breaks down.
Why Self-Reported Confidence Fails
Most chatbot platforms expose a "confidence score" that reflects the model's internal certainty about its intent classification or response selection. Zendesk sets a default threshold at 70%. Many platforms recommend somewhere between 50% and 70% as the sweet spot.
The problem is that these scores measure how sure the model feels, not how accurate it is. MIT's 2026 research showed that asking the same model multiple times (self-consistency checks) fails to detect when a model is confidently wrong. For ecommerce chatbots, cross-model disagreement, where you compare outputs from different LLMs, is far more reliable for uncertainty estimation.
As we covered in The 3% hallucination fallacy, the widely-cited benchmark only measures errors when facts exist in context. The real risk is ungrounded hallucination, when the knowledge base simply doesn't contain the answer and the LLM fills the gap on its own.
Three Response Outcomes: Full Answer, Surgical Fix, or Hard Refusal
A faithfulness score creates three distinct zones for every response your ecommerce chatbot generates. Each zone triggers a different action, and each action produces a different customer experience.
Zone 1: Full Answer (100% Grounded)
In e-commerce, every claim in the response traces to verified data in a source. The AI delivers the answer with citations or source links. No hedging, no caveats. This is where your AI works exactly as intended for products across your catalog, enabling accurate personalization.
For example, a shopper asks "What ingredients are in the Dewy Skin Cream?" and every ingredient listed maps directly to the product catalog and inventory data entry. The response goes straight to the customer.
Zone 2: Surgical Correction (Borderline Scores)
The response contains a mix of validated and unvalidated claims. Rather than discarding the entire answer, the HallucinatedAnswerCorrector takes the original response and the list of unvalidated entities, then runs a deterministic (temperature=0) LLM call with a JSON-schema-constrained output. It returns a corrected answer that removes or neutralizes the hallucinated entities while preserving the rest.
This is where Alhena's self-correcting AI keeps a useful, accurate reply on screen instead of forcing a full refusal. If the AI correctly identifies a product's ingredients but fabricates the price, the corrector strips the price claim and preserves the ingredient list. The customer never sees the hallucinated version.
Zone 3: Hard Refusal (Below Threshold)
For entities extracted by regex (URLs, email addresses, UUIDs), there is zero tolerance for LLM-inferred matches. If a URL or email doesn't appear verbatim in the context, it's hallucinated, period. The system replaces the entire response with "Answer not found." A refusal is always safer than a plausibly-wrong URL a customer might click, or a support email that bounces.
This is the least satisfying customer experience, but brands can recover from that. It's infinitely better than the alternative. Since the 2024 legal precedents, courts have ruled that companies bear legal liability for chatbot-provided information, and Gartner expects over 2,000 AI-related legal claims by end of 2026. A wrong refusal costs you one conversation. A confident hallucination can cost a lawsuit.
Where to Set the Line: Why a Supplement Brand Isn't a T-Shirt Brand
The threshold decision isn't a technical setting. It's a risk tolerance choice that depends on what products you sell and what happens when your AI gets it wrong.
In e-commerce, a wrong fabric care suggestion for a cotton t-shirt is annoying. A wrong allergen claim for a dietary supplement in ecommerce is dangerous. A fabricated compatibility spec for electronics causes returns and frustration. A fictional return policy for a luxury handbag erodes trust among customers of a brand built on exclusivity.
Threshold Ranges by Vertical
- Fashion and apparel (60-70%): Low regulatory risk. Subjective style advice is expected. The cost of a wrong answer is a return, not a safety incident. Fashion brands can afford to give customers increased coverage with slightly lower precision.
- General ecommerce (65-75%): A balanced ecommerce starting point. Most ecommerce product queries have clear right and wrong answers to product questions, but mistakes are recoverable, customers can recover can be made whole.
- Health, beauty, and supplements (80%+): Customers asking about ingredient claims, dosage information, and allergen data carry regulatory weight. The FTC and FDA watch health claims closely. Beauty and skincare brands need high accuracy on ingredient-level questions, where a wrong claim about allergens or contraindications creates real liability.
- Electronics and technical products (75-85%): Products with compatibility and specification claims must be exact. "Works with iPhone 15" is either true or false, with no middle ground.
In ecommerce, below 40% confidence, every vertical should route to a human. And if the AI drops below 50% confidence on two consecutive responses in the same conversation, that's a signal the topic is outside its training data and the customer’s intent needs human judgment. Auto-escalate.
The Too-Strict Trap
Setting thresholds too high creates its own problem. If your ecommerce chatbot refuses 30% of questions because the threshold demands near-perfect sourcing, you've built an expensive ecommerce escalation machine instead of a shopping assistant. Customers who hear "I can't help with that" three times in a row leave. Only 26% of Americans trust AI in retail (YouGov), so every successful AI answer helps build is a chance to build confidence, and every unnecessary refusal fails to increase it wastes it.
The ecommerce calibration exercise isn't "how strict can we be?" It's "what's the cost of being wrong for this specific question type?" A wrong answer about shipping times is a different risk than a wrong answer about drug interactions.
The Shopper Experience at Different Confidence Levels
Threshold settings are abstractions. What matters is what shoppers actually see. Here's how different confidence bands translate to real interactions.
90%+ Confidence: Full Answer with Sources
The AI responds directly and completely. "The Dewy Skin Cream contains hyaluronic acid, Japanese purple rice, and Okinawa algae blend. It's suitable for all skin types." If the brand has configured source data attribution, the response includes a link to the product page.
This is the ecommerce gold standard. Alhena's Product Expert Agent pulls from five parallel retrievers in its agentic architecture, including knowledge graph entity-relationship data, to hit this bar on the majority of product questions.
70-89% Confidence: Hedged Answer with Escalation Offer
The AI has a partial answer but can't fully verify every claim. The response softens: "Based on the product information I have, the Dewy Skin Cream is designed for normal to dry skin types. For specific concerns about sensitive skin, I can connect you with our skincare team."
The hedging language ("based on what I can find") signals uncertainty without abandoning shoppers. The escalation offer gives them a clear follow-up path that matches their intent. This is the zone where Alhena's Support Concierge blends automation with human backup.
40-69% Confidence: Partial Answer with Handoff
The AI shares only what it can verify and routes the rest. "I can confirm this product is currently in stock. For detailed questions about ingredients and allergens, let me connect you with a specialist who can help." The response doesn't guess. It gives what it knows and hands off what it doesn't.
Below 40% Confidence: Clean Human Handoff
No ecommerce answer attempt at all. "That's a great question, and I want to make sure you get the right answer. Let me connect you with our customer service team for expert customer service." The AI acknowledges the question, validates the customer's purchase intent, and steps aside. A clean handoff, done well, can increase trust than a fabricated answer. The customer gets help; the brand avoids liability.
The Performance Gate: Why Not Every Response Gets Validated
Faithfulness validation isn't free. Each extracted fact becomes its own LLM validation call. For a response with eight claims, that's eight calls on top of generation. Ecommerce latency is instrumented per stage (fact_faithfulness_time_taken, entity_faithfulness_time_taken) so the cost is observable, not hidden.
That's why enterprise production AI systems and ecommerce systems use a performance gate. Responses with fewer than a minimum number of factual claims (typically three) skip the validation systems pipeline entirely. A simple "Yes, we offer free shipping on orders over $50" doesn't need the same scrutiny as a detailed comparison of two products' ingredient lists.
This e-commerce threshold, often configured as a parameter like NUM_FACTS_TO_ENABLE_VALIDATION, creates a cost-safety balance. Set it too low and you're validating every greeting. Set it too high and complex answers slip through unchecked.
How Brands Calibrate the Cost-Safety Balance
The right setting depends on your ecommerce query volume, pricing tier and price sensitivity, and average response complexity and data volume. A high-traffic fashion retailer serving millions of customers processing 50,000 AI conversations per month might set the gate at three facts, knowing that most "what size should I get?" questions are simple enough to trust. A supplements brand processing 5,000 conversations might set it at two, validating more aggressively because the cost of a wrong ingredient claim outweighs the added latency.
In ecommerce, semantic caching helps offset the cost. Research shows 31% of enterprise queries are semantically identical, meaning their validation results can be cached and reused. Complexity-based routing, which sends simple queries to faster models and complex ones to more capable models, can reduce LLM usage by 37-46%.
Alhena's pricing accounts for this validation overhead and price. Rather than charging per API call and penalizing brands for being thorough, the platform bundles validation into the conversation cost so brands aren't forced to choose between accuracy and budget, giving ecommerce brands clear ROI on sales lift and revenue. The ROI from increased revenue on their AI investment.
The Alerting and Learning Loop: From Flagged Fact to Fixed Knowledge
For ecommerce brands, catching a hallucination in real time is only half the ecommerce quality job. The other half is making sure the same e-commerce hallucination doesn't happen again.
When the validation layer labels a fact NOT_INFERRED, an alert email fires with the exact unvalidated facts and the ecommerce validator's reasoning. The full result (faithfulness score, validated facts, validated entities, response text, user query, and bot_profile_key) is logged to BigQuery as a structured data record, with validated_facts and validated_entities stored as repeated fields. The conversation gets flagged for review in the quality control dashboard.
Alongside fact-level validation, the system runs a parallel entity pipeline. In ecommerce, an EntitiesExtractor combines LLM-based named entity recognition (brands, products, people) with regex extraction (URLs, emails, UUIDs). Each entity is typed and validated in two tiers: exact string match against the full context first, then LLM inference as a fallback. Three separate metrics (entity_faithfulness overall, llm_entity_faithfulness, and deterministic_entity_faithfulness) make regressions easy to isolate.
Turning Failures into Knowledge Base Improvements
The real value of structured logging isn't catching individual errors. It's pattern detection. Patterns in. When the same product question triggers NOT_INFERRED flags repeatedly, that's a signal the knowledge base data has a gap, not that the AI is broken.
Alhena's quality assurance framework operates on three tiers: automated watchdogs that flag low-confidence responses in real time, weekly sampling of 2-5% of conversations against ecommerce accuracy standards using data from production data, and exception-based review where every customer escalation and negative CSAT score triggers investigation. The flagging rate stays low because the validation pipeline catches most issues before they reach customers. Each flag feeds back into the knowledge graph, closing e-commerce knowledge gaps that caused the uncertainty in ecommerce interactions.
This loop is what separates a static chatbot from a self-improving ecommerce system. Brands like Manawa, which cut agent workload by 43% and response times from 40 minutes to under 1 minute, got there (as documented in their case study) not by launching perfectly but by running this feedback cycle continuously, increasing sales conversions and revenue at every step.
Setting Your Thresholds: A Practical Starting Point
If you're deploying AI for ecommerce today, here's where to start:
- Audit your question types. Pull your last 1,000 customer questions and categorize them by risk level. Inventory and availability questions. Product availability? Low risk. Ingredient safety? High risk. Return policy? Medium risk. Pricing data? Medium risk. The e-commerce risk profile. The distribution tells you how strict your average threshold needs to be.
- Set vertical-appropriate defaults. Fashion and general retail: 65-70%. Health, beauty, and supplements: 80%+. Electronics and technical: 75-80%. Adjust from there based on your flagging rate and ROI targets.
- Configure the performance gate. Start with a fact threshold of three. Monitor your validation costs for the first two weeks. If costs are manageable, lower it to two. If latency spikes, raise it to four.
- Build the escalation path first. Before you go live, make sure the handoff to human agents works smoothly. A clean "I don't know" that routes to a knowledgeable agent is better than a hallucinated answer followed by a complaint.
- Review flagged conversations weekly. Use a brand safety audit checklist to structure the review. Look for patterns: if the same topic triggers flags repeatedly, update the knowledge base rather than loosening the threshold.
The pressure to ship AI fast is real, but so are the consequences of shipping it wrong. The difference between brands that build customer trust and brands that face regulatory scrutiny comes down to one question: did you design your uncertainty thresholds before going live, or did you find out about them from customer complaints?
Ready to deploy ecommerce AI that knows when to answer and when to escalate? Schedule a demo to see threshold calibration, surgical correction, and the full validation pipeline in action, or start free with 25 conversations to test accuracy yourself.

Frequently Asked Questions
What is a faithfulness score in AI chatbots?
A faithfulness score measures how many claims in an AI response can be traced back to the context the LLM actually received. Alhena's FactsExtractor enumerates every factual statement, then a FactValidator checks each against the RAG context, tool outputs, and chat history, labeling it DIRECTLY_INFERRED, INDIRECTLY_INFERRED, or NOT_INFERRED. The score is validated facts divided by total facts, times 100%.
How do AI uncertainty thresholds prevent ecommerce chatbot hallucinations?
Uncertainty thresholds set the minimum faithfulness score required before an AI response reaches the customer. In ecommerce, responses above the threshold go through as full answers. Borderline responses get surgically corrected, with unvalidated claims removed while verified facts remain. Responses below the threshold trigger a hard refusal and human handoff instead of risking inaccurate information.
What confidence threshold should an ecommerce chatbot use?
The right threshold depends on your vertical risk. Fashion and apparel brands can start at 60-70% because wrong style advice is low-stakes. Health, beauty, and supplement brands should use 80%+ because ingredient and allergen errors carry regulatory and safety risk. General ecommerce sits at 65-75%. Below 40%, every vertical should route to a human agent regardless.
What happens when an AI chatbot is not confident in its answer?
The response changes based on the confidence level. At 70-89%, the AI gives a hedged answer with language like "based on what I can find" and offers to escalate. At 40-69%, it shares only verified facts and hands off the rest to a human. Below 40%, it skips the answer entirely and connects the shopper with a live agent. Each tier is designed to maintain trust rather than risk a wrong answer.
How does Alhena AI prevent hallucinations differently from other chatbots?
Alhena runs a four-layer pipeline on every response: (1) a FactsExtractor and FactValidator ground every factual claim against retrieved context and tool outputs, (2) an EntitiesExtractor with regex and LLM extraction verifies every entity via exact string match plus LLM fallback, (3) regex-extracted identifiers like URLs, emails, and UUIDs face zero-tolerance refusal if not verbatim in context, and (4) the HallucinatedAnswerCorrector surgically removes unvalidated entities at temperature=0 instead of discarding the entire reply. This achieves sub-0.1% hallucination rates in production.
What is the performance gate in AI response validation?
The performance gate is a threshold (NUM_FACTS_TO_ENABLE_VALIDATION, default 3) that determines which responses get full validation. Ecommerce chatbot responses with fewer facts than the threshold skip the pipeline to save latency. Latency is instrumented per stage (fact_faithfulness_time_taken, entity_faithfulness_time_taken) so cost is observable. Brands calibrate this based on query volume and vertical risk.
How do brands track and measure AI hallucination rates over time?
Every validation result is logged to BigQuery as a structured record containing the faithfulness score, validated_facts and validated_entities as repeated fields, the response text, user query, and bot_profile_key. This creates a queryable hallucination dataset you can slice by bot profile, entity type, faithfulness score, or time period. NOT_INFERRED facts trigger alert emails with the validator's reasoning, and three separate entity metrics (overall, LLM-only, deterministic-only) make it easy to isolate regressions.
Can AI chatbots be legally liable for giving wrong information?
Yes. Courts have ruled that companies are responsible for all information their AI provides to customers, even when it contradicts official policies. Gartner predicts AI-related legal claims will exceed 2,000 by end of 2026. The legal precedent is clear: if your chatbot gives wrong information, you own the consequences. This is why hard refusal at low confidence is a legal safeguard, not just a UX decision.