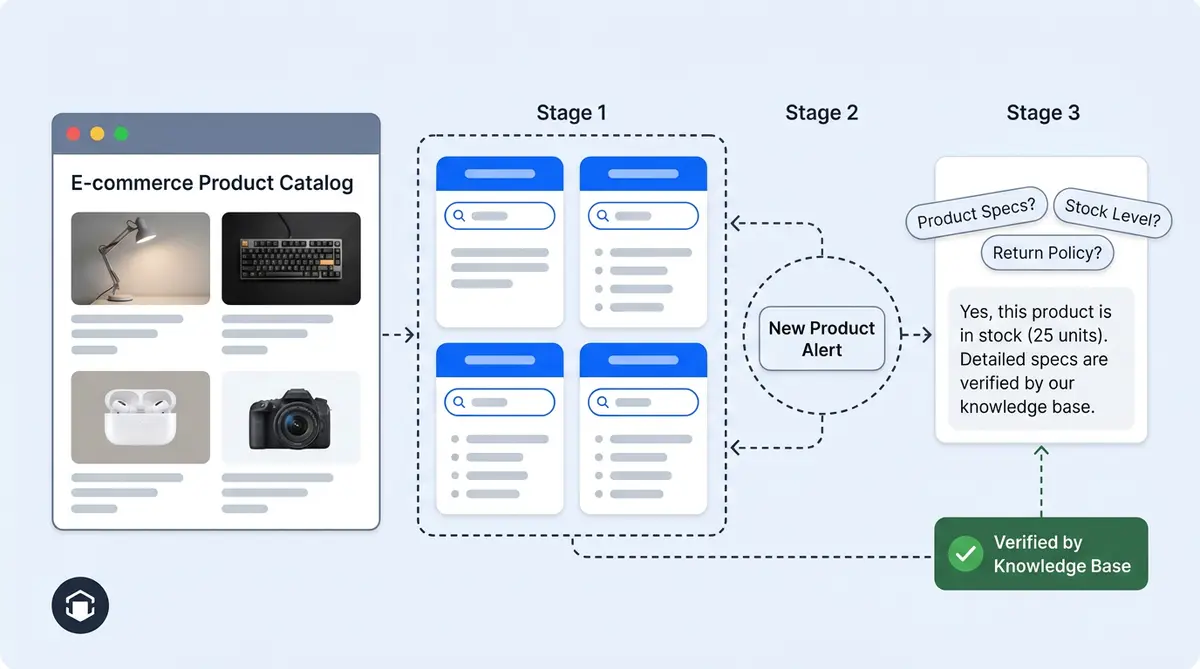
The Long-Tail Problem You Can't Solve by Hand
E-commerce brands get an enormous variety of customer questions, but the distribution is extremely long-tailed. The head, things like "What's your return policy?" and "How much does shipping cost?", is small and predictable. The tail, queries like "Do these wireless earbuds stay put when I'm running with small ears?" or "Which memory foam mattress works for back pain under $800?", is where the real volume lives.
You can't hand-write training data for the tail. There are too many combinations of category, attribute, price, use case, and persona. According to Embryo, 91.8% of all search queries are long-tail keywords, and Google confirms that 15% of daily searches have never been seen before. So Alhena synthesizes it: synthetic data generation of realistic customer queries grounded in the merchant's actual catalog and taxonomy, then using those queries to handle model training, validation, and performance measurement via machine learning.
This post covers the six generators that make it work, and the three-layer architecture (bootstrap, maintenance, runtime) that keeps synthetic training data current as catalogs change.
The Pipeline: Six Generators, One Goal
1. Product Search Starter Generator
This is the workhorse for long-tail coverage, targeting the search engine and information retrieval queries that matter most. It pulls the merchant's product taxonomy (categories to subcategories to attributes) from the ProductTaxonomy table, then queries Qdrant for a random sample of variants per subcategory to compute a median price per category-subcategory pair.
It then prompts a large language model (LLM) via generative AI to generate queries across four intent buckets in equal 25% distribution:
- Broad category: "Show me chairs that are comfortable"
- Specific subcategory: "Do you have any ergonomic office chairs?"
- Price-range (anchored at median ±10%): "Can I find an office chair for about $110?"
- Attribute-specific: "I'm looking for a red office chair"
The median-price anchoring is the key detail. This data quality check ensures real world shopper budgets are reflected for this specific catalog, not made-up numbers. A $45 median generates "moisturizers under $50," not a hallucinated $200 threshold.
2. Per-Product FAQ Generator
For every product URL, this pulls the product's content from the vector store (falling back to live-scraping the page if missing) and prompts Gemini to produce two question sets: category-specific questions asked during the awareness stage ("What should I consider when buying X?") and product-specific questions asked during the consideration stage ("Is this suitable for sensitive skin?"). Up to 15 of each, ranked, with a hard rule: every question must be answerable from the product content itself. No hallucinated questions. Variant-level attributes like price, size, and color are explicitly excluded since those are already visible on the PDP.
3. AEO Query Expansion Generator
This query generation engine is tuned for Answer Engine Optimization, creating the queries a real shopper would type into ChatGPT, Perplexity, or AI Overviews. It outputs queries across five commercial-intent buckets: product discovery (50%), price/value (20%), comparison (10%), trending (10%), and competitor (10%).
Two anti-bias rules are strictly enforced. First, never mention the target brand. If the merchant is "Acme," queries must read like a shopper who's never heard of Acme. Second, never reference specific SKUs or proprietary features. A "Titanium Trail Runner with Carbon Plate" becomes the abstract "best carbon plate trail running shoes for beginners." This keeps data augmentation unbiased and avoids privacy issues from using real customer queries, which matters because Alhena uses it to measure whether AI engines naturally surface the brand.
4. Keyword-Grounded Long-Tail Extraction
Before expanding any query, Alhena decomposes it into keywords and tags each as long-tail (3+ word phrases with specific intent) or short-tail (1-2 word broad terms). Long-tail keywords are weighted higher because they capture real purchase intent. Then a KeywordVolumeFetcher calls DataForSEO to attach actual search volume per keyword.
The result: instead of generating synthetic queries blindly, Alhena generates queries anchored to keywords that real shoppers actually search for, with verified volume data. The query-expansion LLM uses these as seed foundations and expands them into full conversational queries.
5. Related Questions and Icebreakers
These run at conversation time, not batch time. Icebreakers are generated per product page from crawled page content. Short, conversational openers ("What sizes are available?", "How do I apply this?") seed the chatbot widget before the user types anything. Related Questions fire after the AI answers a query, generated from the answer plus the retrieved knowledge chunk. Strict rules apply: every follow-up must be answerable with accuracy from the retrieved knowledge, no full product names, no asking about price (already on the card), and certain flows (order status, human handoff) return an empty list.
6. Canned Response Reverse Generator
This one works in the opposite direction. Merchants write answers as Zendesk, Gorgias, or Freshdesk macros. This generator takes each answer and reverse-generates the customer question that would trigger it. That question gets embedded into the vector store so future long-tail user queries route to the correct canned response, even when phrasing diverges completely from the macro's original wording. This is a direct extension of the agentic chunking approach Alhena uses for knowledge base content.
Three Layers: Bootstrap, Maintenance, Runtime
Layer 1: Bootstrap (Onboarding)
When a new merchant connects, all batch generators fire in the first crawl cycle. The Product FAQ Generator runs for every product URL as the training pipeline crawls each page. The Search Starter Generator runs once the ProductTaxonomy table is populated. The Canned Response Reverse Generator processes every helpdesk macro on first ingest. The AEO baseline expands seed keywords into hundreds of shopper queries. A merchant with a 5,000-SKU catalog ends up with tens of thousands of realistic synthetic queries spanning every category, price, attribute, and intent combination, through full automation, without manual data labeling.
Layer 2: Maintenance (Ongoing)
The generators re-fire whenever their source material changes, keeping production data current after every deploy so nothing goes stale:
- Product page re-crawled (refresh job or Shopify webhook): FAQs regenerate for that product, icebreakers invalidate and regenerate
- New products added or taxonomy updated: Search Starter re-samples, computes new median prices from Qdrant, produces new queries
- Helpdesk macros added or edited: Canned Response Reverse Generator runs on the delta and re-embeds
- Scheduled AEO analysis: Query expansion re-runs with current trending-topic context, so "trending 2025-2026" queries stay fresh
- Keyword volume refresh: DataForSEO volumes are re-fetched, long-tail vs. short-tail tags recomputed
This is why knowledge base ops matter so much. The maintenance layer follows the catalog, the macros, and shopper behavior trends. Compare this to the manual annotation model, where a human team would need re-briefing and re-QA every time anything shifts.
Layer 3: Runtime (Per Turn)
Two generators don't batch at all. Related Questions fire after every AI answer, reading the retrieved knowledge plus the response to produce 3 to 5 grounded follow-up questions. Dynamic Icebreakers synthesize on the fly when a shopper lands on a product page that hasn't been cached yet. Both serve a dual purpose: they guide shoppers toward answers that exist, improving personalization and customer experience and they generate real interaction data that feeds back into the self-improving AI loop.
The Design Rule: Generate Questions, Never Fabricate Answers
Every generator in this pipeline creates questions, not answers. Questions are cheap, safe, and low-risk. A bad question just means the retrieval system finds no match and the shopper gets a fallback response. No harm done.
Synthetic answers are a different story. A fabricated answer about product ingredients, sizing, or return policies can mislead a customer. This is why Alhena never generates synthetic answers. When the AI encounters a question it can't answer, it says "I don't know" and flags the conversation. A human reviews the unanswered question and provides the correct response. That correction triggers FaqGeneratorV2, which creates a canonical Q&A pair from the human input. The new pair enters the knowledge base permanently, closing the gap for every future variation of that question.
This creates a flywheel: synthetic questions expose knowledge gaps. Gaps trigger human corrections. Corrections generate canonical FAQ pairs. Those pairs close the gaps permanently. NVIDIA's Nemotron-4 project showed that over 98% of fine-tuning and alignment data can be synthetically generated alongside real-world data without quality loss, but only when grounded in real source material. Alhena applies the same principle to ecommerce catalogs.
Why This Architecture Works
Five properties make this system reliable and scalable. First, it's grounded, not hallucinated: every generator pulls from ground truth catalog data (taxonomy, product content, median prices, crawled pages), then constrains the deep learning model (neural network) to only produce questions answerable from that data. Second, it's distribution-aware: fixed intent-bucket percentages guarantee coverage of the whole long tail, not just the easy head. Third, it's anti-biased by construction: AEO generators explicitly ban brand-name leakage so synthetic queries stay representative of real shopper behavior. Fourth, it's volume-calibrated: DataForSEO integration means synthetic queries are anchored to keywords with proven search volume, not invented ones. And fifth, it's multi-timeframe: some generators run at batch/onboarding, some at conversation time, so coverage stays fresh as the catalog and shopper behavior evolve.
The net effect: a merchant with a 5,000-SKU catalog ends up with tens of thousands of realistic synthetic queries spanning every category, price, attribute, and intent combination. Brands like Tatcha (3x conversion rate, 11.4% of total site revenue) and Puffy (63% automated resolution, 90% CSAT) run on this foundation.
Ready to see how Alhena covers your catalog's long tail from day one? Book a demo or start free with 25 conversations to test it against your own product catalog.

Frequently Asked Questions
What is synthetic training data for ecommerce AI?
Synthetic training data consists of programmatically generated queries that teach AI systems to understand the full range of how shoppers search. Instead of human writers anticipating every query variation, generators create thousands of queries grounded in real catalog data, covering price ranges, product attributes, and natural language processing (NLP) phrasing patterns across the long tail of ecommerce search.
How many generators does Alhena use for synthetic training data?
Alhena runs six generators: the Product Search Starter Generator (taxonomy-based search queries), Per-Product FAQ Generator (up to 30 Q&As per product page), AEO Query Expansion Generator (shopper queries across five intent buckets), Keyword-Grounded Long-Tail Extraction (DataForSEO volume-calibrated keywords), Related Questions and Icebreakers (runtime, per-turn generation), and the Canned Response Reverse Generator (helpdesk macro to question mapping).
How does Alhena prevent hallucinations in synthetic training data?
Alhena only generates synthetic questions, never synthetic answers. Every generated query is grounded in real product data from the catalog, including verified prices, attributes, and taxonomy. Answers always come from the actual knowledge base. When the AI encounters a question it cannot answer, it flags it for human review and the correction triggers FaqGeneratorV2 to create a canonical Q&A pair that closes the gap permanently.
What are the three layers of the synthetic data pipeline?
Layer 1 (Bootstrap) fires all batch generators during onboarding to create initial coverage from the catalog, taxonomy, and helpdesk macros. Layer 2 (Maintenance) re-fires generators whenever products change, macros update, or keyword volumes shift via DataForSEO. Layer 3 (Runtime) generates Related Questions and Icebreakers live during each conversation, grounded in retrieved knowledge so every suggestion leads to a real answer.
How does the AEO Query Expansion Generator avoid bias?
Two strict anti-bias rules apply. First, the generator never mentions the target brand in any query, so results read like a shopper who has never heard of the merchant. Second, it never references specific SKUs or proprietary product names. This keeps synthetic data representative of real, unbiased shopper behavior for Answer Engine Optimization testing.
Does synthetic training data stay current when the catalog changes?
Yes. The maintenance layer re-fires generators whenever products are added, updated, or removed. Price-range queries adjust to new median prices recomputed from Qdrant. FAQs and icebreakers regenerate when product pages are re-crawled. The Canned Response Reverse Generator runs on the delta when helpdesk macros are added or edited. AEO queries refresh with current trending-topic context so seasonal terms stay accurate.
What is the Canned Response Reverse Generator?
It takes existing customer support macros from Zendesk, Gorgias, or Freshdesk and reverse-generates the range of customer questions that would trigger each macro answer. Those questions get embedding vectors stored in the vector database so the retrieval system can match future paraphrases to the correct canned response, even when the phrasing diverges completely from the original macro wording.
How does keyword-grounded extraction improve synthetic query quality?
Before expanding any query, Alhena decomposes it into keywords tagged as long-tail (3+ words with specific intent) or short-tail (1-2 broad words). Long-tail keywords are weighted higher for purchase intent. DataForSEO attaches actual search volume data to each keyword. The query-expansion LLM then uses these verified, volume-calibrated keywords as seed foundations, producing synthetic queries anchored to terms real shoppers actually search for.


