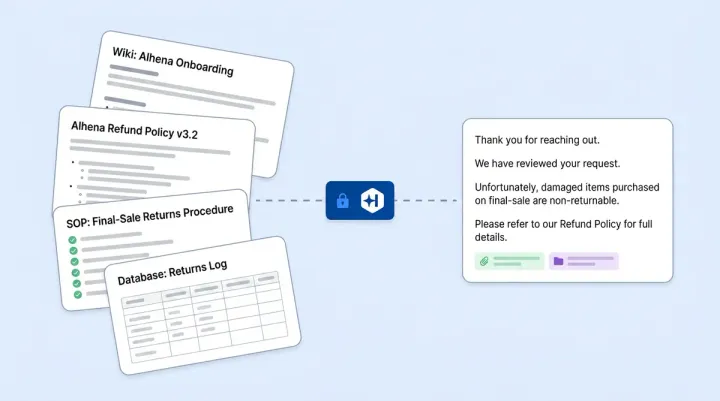
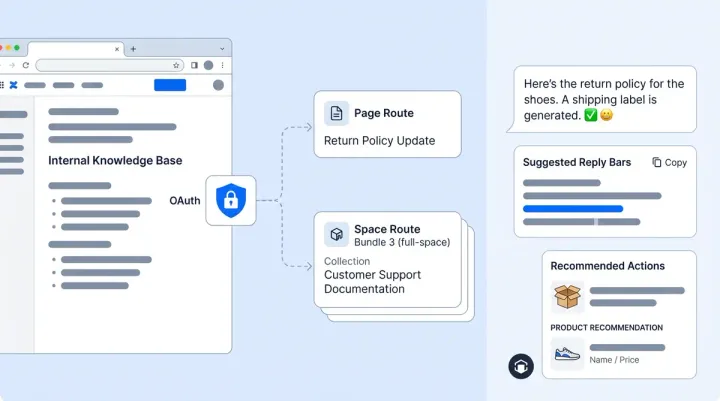
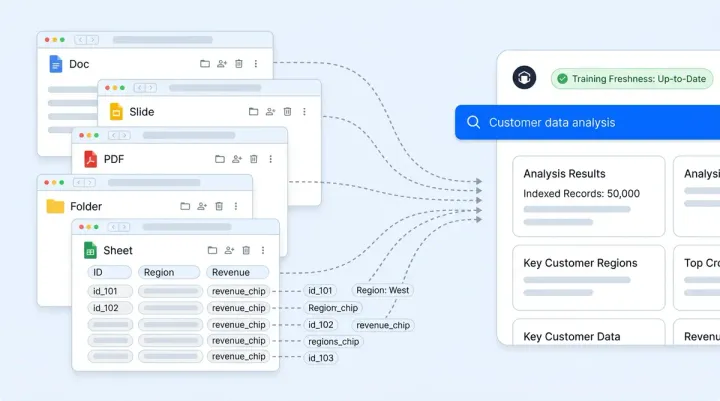
A 10% AI escalation rate sounds great until you realize the AI is quietly botching refund requests and tanking your CSAT. A 40% rate sounds terrible until you learn the brand sells medical devices and regulations demand human review on half of inbound tickets. Escalation rate, the percentage of AI conversations handed off to a human agent, is the most misunderstood metric in AI-powered customer support. The number alone tells you almost nothing. What matters is whether each escalation was correct.
This post breaks down how to audit your escalation rate, quantify what bad escalations cost, and build a monthly review cadence that tightens performance over time.
Why a "Good" Escalation Rate Depends on Context
There's no universal target. An online beauty brand with simple "where's my order?" volume might run at 15%. A luxury furniture store fielding custom-dimension questions and white-glove delivery coordination could sit at 35% and still be well-optimized. What determines the right number is your ticket mix (how many inquiry types genuinely need a human), your vertical risk profile (regulated products and services, high AOV, brand-sensitive categories), and what the AI is actually resolving versus just closing.
Gartner found that only 14% of customer service issues are fully resolved through self-service, which means even mature AI deployments should expect meaningful escalation volume. Benchmarking against industry averages and vertical norms is a starting point, not an answer. The real question is whether the tickets your AI escalates should have been escalated, and whether the customer tickets it keeps should have stayed.
False Escalations: The Hidden Cost of Over-Cautious AI
False escalations are conversations the AI routed to a human agent that it could have resolved on its own. They're the most common waste in AI support and the easiest to fix. Every false escalation costs you $8 to $15 in agent handling time, compared to $0.50 to $2 for an AI resolution. At scale, even a 5% reduction in false escalations saves thousands per month.
How to find them: pull a sample of 50 escalated transcripts every week. For each one, ask a simple question: could the AI have resolved this with information already in its knowledge base? Common examples include order status lookups where the AI had tracking data but escalated anyway, return policy questions the AI answered partially before handing off, and product questions the AI could have pulled from catalog data. Tag each false escalation by ticket category so patterns emerge. After two weeks, you'll know exactly which AI coaching adjustments to make.
Missed Escalations: When the AI Should Have Stepped Back
Missed escalations are the dangerous ones. These are tickets the AI attempted to resolve that genuinely needed a human, and the customer either got a wrong answer, a generic deflection, or a frustrating loop. The damage shows up as low CSAT on AI-handled conversations, follow-up tickets within 48 hours on the same issue, and social media complaints about "talking to a wall." According to PwC, 52% of consumers will abandon a brand after a single bad support experience.
To catch them, correlate your lowest-CSAT AI conversations with ticket type. If AI-handled warranty claims score 30 points below your average, that's a signal the AI is over-handling that category. Confidence-threshold tuning lets you set the AI to escalate when its certainty drops below a defined level, so it says "let me connect you with a specialist" instead of guessing. Alhena AI's Support Concierge uses grounded responses tied to verified product data, which reduces missed escalations by eliminating hallucinated answers at the source.
The Cost-Per-Escalation Math
Here's a simplified model. Say your team handles 5,000 AI conversations per month with a 25% escalation rate (1,250 escalated tickets). If your transcript review reveals that 20% of those escalations were false, that's 250 tickets your agents handled for no reason.
Gartner benchmarks put self-service contacts at $1.84 versus $13.50 for agent-assisted ones. At an average agent cost of $12 per interaction, those 250 false escalations cost $3,000 per month. Reducing false escalations by just 5 percentage points (from 20% to 15%) saves $750/month, or $9,000/year, without changing your AI's coverage at all. You're just routing smarter. For ecommerce businesses processing higher volumes, these numbers multiply fast. Alhena's built-in analytics dashboard tracks escalation rates by ticket category so you can run this math on real data, not estimates.
The Monthly Escalation Review Cadence
Optimization isn't a one-time project. Build a monthly loop:
- Pull escalation rate by ticket type. Don't look at the aggregate number. Break it down: order status, returns, product questions, shipping issues, complaints.
- Identify the top 3 categories with the highest false-escalation rate. These are your quick wins.
- Tighten thresholds on those categories. Update your AI's confidence settings, expand its knowledge base entries, or add escalation trigger rules that are more specific.
- Check for missed escalations. Look at categories where AI-handled CSAT is significantly below agent-handled CSAT. Widen thresholds there so more tickets route to humans.
- Re-measure next month. Compare false and missed escalation rates against your baseline to track improvements.
This cadence pairs well with a weekly AI visibility workflow where you monitor real-time trends between monthly deep dives.
The Escalation Quality Score: Precision and Recall for Support
Most teams track whether the AI escalated. Fewer measure the more important question: whether the escalation was correct. Borrowing from machine learning, you can define two metrics:
- Escalation precision: Of all conversations the AI escalated, what percentage truly needed a human? High precision means few false escalations.
- Escalation recall: Of all conversations that genuinely needed a human, what percentage did the AI actually escalate? High recall means few missed escalations.
The ideal is high on both, but there's always a tradeoff. Pushing for near-zero false escalations (high precision) risks more missed escalations (low recall), and vice versa. For most ecommerce brands, recall matters more: a missed escalation on a $500 order costs far more than an agent spending five minutes on a ticket the AI could have handled. Start by tracking both monthly, then optimize toward the balance that matches your risk tolerance.
Alhena AI gives you the data to run this analysis out of the box. Support KPIs like containment rate, CSAT, and first-response time feed directly into escalation quality scoring when you pair them with transcript-level escalation tagging.
Ready to find out if your AI is escalating too much, too little, or just right? Book a demo with Alhena AI to see how escalation analytics work in practice, or start free with 25 conversations to test it yourself.

Frequently Asked Questions
What is a good AI escalation rate for ecommerce?
There's no single target. It depends on your ticket mix, product complexity, and vertical risk. Beauty brands with simple order inquiries may run at 12-18%, while luxury or regulated verticals often sit at 30-40%. The right rate is one where false and missed escalations are both low.
How do I identify false escalations in my AI support?
Review 50 escalated transcripts weekly and ask: could the AI have resolved this with existing knowledge base data? Tag each false escalation by ticket category. Common offenders include order tracking lookups and return policy questions the AI already had answers for.
What do false escalations cost my support team?
Each unnecessary escalation costs $8 to $15 in agent handling time, compared to $0.50 to $2 for AI resolution. A team with 1,250 monthly escalations and a 20% false-escalation rate wastes roughly $3,000 per month on tickets the AI could have handled.
How do I catch missed escalations before they hurt CSAT?
Correlate CSAT scores on AI-handled tickets with ticket type. Categories where AI-handled CSAT runs significantly below agent-handled CSAT signal over-handling. Follow-up tickets within 48 hours on the same issue are another strong indicator.
What is escalation precision and recall?
Escalation precision measures what percentage of AI-escalated conversations truly needed a human. Escalation recall measures what percentage of conversations that needed a human actually got escalated. For ecommerce, recall typically matters more because missed escalations on high-value orders carry higher risk.
How often should I review my AI escalation rate?
Run a full escalation audit monthly. Break escalation rate down by ticket type, identify the top 3 categories with the highest false-escalation rate, tighten thresholds there, and widen thresholds on categories where AI CSAT is low. Track trends month over month.
How does Alhena AI help optimize escalation rates?
Alhena AI tracks escalation rates by ticket category in its analytics dashboard, uses confidence-threshold tuning to control when the AI hands off, and grounds all responses in verified product data to reduce hallucination-driven missed escalations. Brands like Puffy achieve 63% automated resolution with 90% CSAT using this approach.