Model choice gets all the attention. But for e-commerce AI, what you feed the model matters more than which model you pick. Retrieval architecture is the accuracy ceiling, and most shopping assistants hit that ceiling fast because they rely on a single retrieval pipeline with a clear limitation: no structural reasoning.
Alhena AI uses two: a Retrieval Augmented Generation (RAG) vector store and a knowledge graph, working together, combining both approaches in one hybrid search system. This post explains this hybrid approach: why both exist, when each one fires, and how the architecture keeps answers grounded in verified product data.
Where Vector Search Excels (and Where It Doesn't)
Vector search uses embedding models to convert documents into dense vectors (numerical representations) and finds the closest matches to retrieve relevant passages. It's excellent at semantic similarity and complements traditional keyword search methods like BM25 scoring and lexical matching. A shopper using natural language like "lightweight rain jacket for hiking" will get relevant results even if no product description uses those exact words.
But vector search struggles with three types of e-commerce queries:
- Multi-hop reasoning: "Can I return the gift my sister bought me 45 days ago under your holiday policy?" This requires connecting an order, a person, a time window, and a policy. Chunks of text don't encode those relationships.
- Entity disambiguation: Two products with overlapping names, or a SKU vs a variant vs a bundle. Embedding similarity can't reliably distinguish them.
- Relationship queries: "Which accessories are compatible with model X?" Compatibility is a typed relationship between entities, not a passage of text.
These aren't edge cases. They're the queries that drive revenue and reduce returns. For a deeper look at why retrieval quality depends on clean product data, see our Catalog-First AI guide.
What a Knowledge Graph Adds
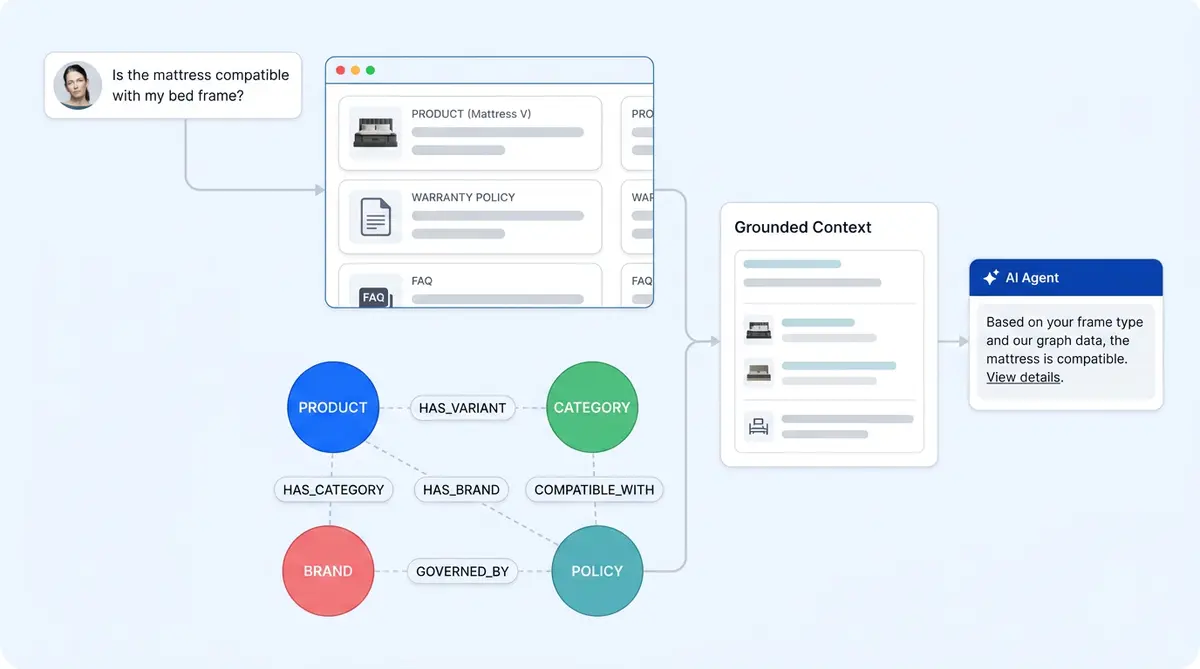
Knowledge graphs store entities (products, variants, policies, categories, brands) and the typed relationships between them: COMPATIBLE_WITH, BELONGS_TO, GOVERNED_BY, SUPERSEDES. Traversing these relationships gives precise, deterministic answers to structural queries.
The tradeoff? Graphs are brittle when the shopper's phrasing doesn't match indexed entity names. They lack the semantic generalization that makes vector search forgiving. Neither approach works well alone. Together, they cover each other's blind spots.
Alhena built both retrieval methods into the same pipeline from day one. We covered why a knowledge graph matters alongside a vector database in a previous post and explored the broader shift from static retrieval to agentic RAG for e-commerce. Here's how the two retrieval legs work together under the hood.
How Alhena's Hybrid Retrieval Works
Alhena's AI Shopping Assistant runs both retrieval paths and fuses the results before the agentic system generates a semantic, grounded response.
The vector leg
Unstructured document content like product pages, policy files, and help articles are chunked, embedded, and stored in a vector store. At query time, the shopper's question is embedded and matched against stored chunks by semantic similarity. This search model handles the broad content-matching "find me something like X" queries well.
The graph leg
During ingestion, Alhena automatically extracts and indexes entities and typed relationships from the same source documents. A configuration tuner samples representative document content per store and infers the relevant domain (apparel, beauty, home goods), entity types, and relationship patterns, so there's no manual ontology building required. This gives the graph scalability across hundreds of product lines.
Extracted entities are deduplicated through entity resolution, then stored in a graph database with their own embeddings. At query time, the graph is queried through a vector index over entity nodes, not through LLM-generated database queries. Matched entities expand into their relationship subgraph, surfacing connections like compatibility, policy applicability, or category membership.
This architecture avoids a common failure mode in GraphRAG systems: letting an LLM write raw database queries, which introduces syntax errors and hallucinated schema references. Alhena sidesteps that entirely.
Fusion
Both data retrieval paths feed into a context layer that the agent consumes alongside live commerce tools (catalog APIs, document lookups, order management APIs, and complex policy engines). The agent sees semantic matches and structural relationships together before generating a response.
When Each Leg Drives the Answer
Three quick examples show how this plays out in practice:
- "Show me a moisturizer for dry, sensitive skin under $50." Vector search dominates. Semantic search matches product descriptions against the shopper's needs and product recommendation logic across your full catalog.
- "Is this serum compatible with the retinol I bought last month?" The graph dominates. Compatibility and ingredient-interaction relationships give a precise answer that vector search would approximate at best.
- "Can I still return my order from six weeks ago?" The graph connects the order entity to the applicable return policy and checks the time window. Live order tools confirm the order status. Vector search alone would return generic return-policy text without knowing whether it applies to this specific order.
These are the queries where e-commerce AI earns its keep: high-intent, complex use cases that a basic chatbot or rule-based bot punts to a human agent.
Grounded, Not Guaranteed
Hybrid retrieval improves accuracy, but no LLM system can guarantee zero hallucinations. Alhena adds verification layers on top of retrieval:
- Source attribution: every response traces back to the chunks and entities that informed it, visible in the Conversation Debugger.
- Deferral: when no grounded source exists, the agent declines to guess and escalates to a human via the Support Concierge.
- Conflict detection: as Alhena's continuous learning system proposes new FAQs, contradictions with existing knowledge are flagged before they merge into the knowledge base.
The honest framing: Alhena is hallucination-resistant, not hallucination-proof. The architecture minimizes the surface area for errors, and the verification layer catches what slips through. For more on how this quality control works, read our post on how AI quality control catches hallucinations before customers notice.
What This Means for Your Store
If you're evaluating AI for your commerce platform, ask one question about retrieval: does its data retrieval handle relationship queries across your catalog, or just keyword matching and similarity scoring? The performance difference in data retrieval quality shows up in conversion rates, recommendation system accuracy, return rates, and the percentage of chats that need human escalation.
Alhena's hybrid retrieval is one reason brands like Tatcha see 3x conversion rates from AI-assisted shopping, and Puffy hits 90% CSAT with 63% automated resolution. The architecture does the retrieval workload so your team doesn't have to.
For a broader look at how Alhena's architecture differs from bolt-on AI tools, see our AI-Native vs AI-Enhanced comparison and our guide to AI shopping assistants.
Ready to see hybrid retrieval in action on your catalog? Book a demo with Alhena AI or start for free with 25 conversations.

Frequently Asked Questions
What is hybrid RAG in e-commerce AI?
Hybrid RAG combines vector search (semantic similarity over document embeddings) with knowledge graph retrieval (entity and relationship lookups). This lets an ecommerce AI handle both natural-language product discovery queries and structured questions about compatibility, policies, or order history.
How does Alhena's knowledge graph differ from a vector database?
A vector database finds semantically similar text chunks. Alhena's knowledge graph stores typed entities (products, policies, categories) and their relationships (COMPATIBLE_WITH, GOVERNED_BY). The graph answers structural questions that vector similarity can't resolve, like which accessories fit a specific model.
Does Alhena use LLM-generated Cypher queries at runtime?
No. Alhena queries the knowledge graph through a vector index over entity-node embeddings, then expands matched entities into their relationship subgraph. This avoids the syntax errors and hallucinated schema references common in LLM-generated database queries.
Is Alhena's AI hallucination-free?
No LLM system can guarantee zero hallucinations. Alhena is hallucination-resistant: hybrid retrieval grounds answers in verified sources, the Conversation Debugger traces every response to its source data, and the agent defers to a human when no grounded answer exists.
Can Alhena's hybrid retrieval handle product compatibility questions?
Yes. The knowledge graph stores typed relationships like COMPATIBLE_WITH between products, accessories, and components. When a shopper asks whether an item works with something they already own, the graph traverses that relationship directly instead of relying on text-chunk similarity. This is one of the highest-value use cases for graph-based retrieval in ecommerce.
How long does it take to set up Alhena's hybrid retrieval on my store?
Alhena deploys in under 48 hours, so you can implement hybrid retrieval with no dev resources needed. The knowledge graph configuration tuner automatically infers your domain, entity types, and relationship patterns from your product catalog and policy documents.