The Catalog Is the Model
Your AI shopping assistant doesn't "know" your products. It retrieves from your catalog, title by title, variant by variant, at the moment a shopper asks. Whether users are browsing for personalized recommendations or searching for a specific item, the smart AI agent on your store can only work with what your data provides. The LLM paraphrases what it finds. That means accuracy is bounded by two things: how well retrieval finds the right rows, and how complete those rows actually are.
For product specs and compatibility tables maintained in spreadsheets, Alhena's Sheet Search provides table-aware retrieval that preserves row and column structure.
Most ecommerce merchants who ask "how clean does my data need to be?" before deploying an AI assistant are asking the right question. This post answers it by walking through the shopping journey pipeline your catalog data travels, where it breaks, and what the silent failures look like.
How a Shopping Query Becomes an AI Answer
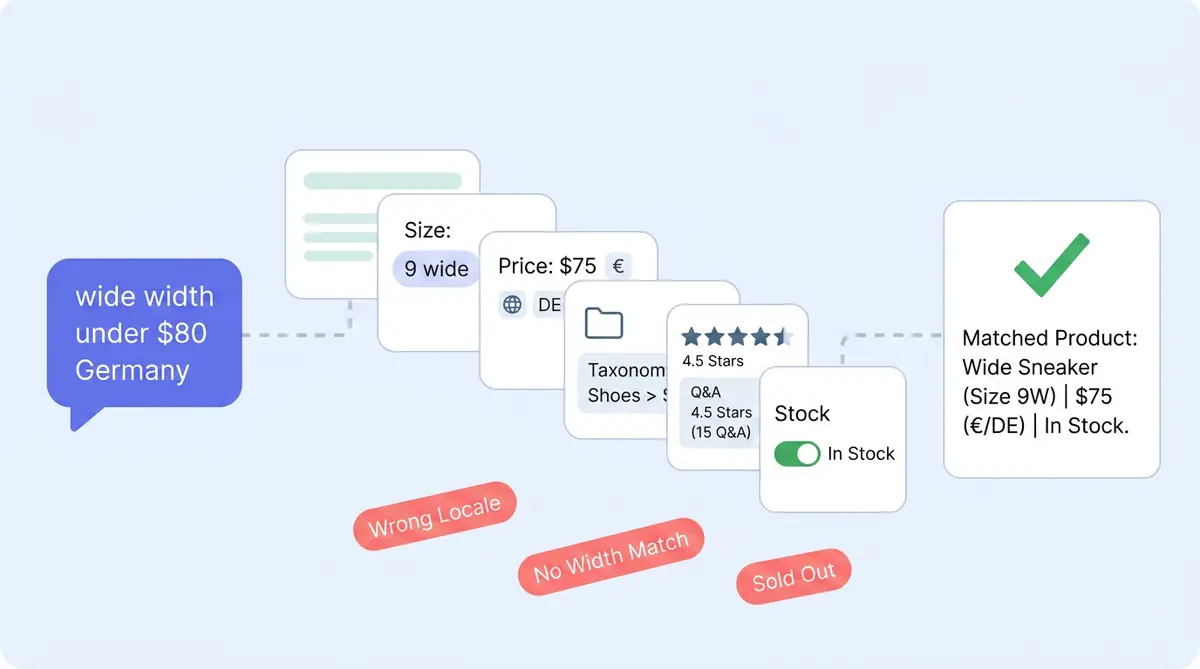
When a customer asks "do you have this in a wide width under $80 that ships to Germany?", the Alhena AI shopping assistant runs through five steps:
- Plan. A planner agent reads the natural language query in an agentic workflow, identifies shopper intent, and decides which retriever to call: catalog, structured attributes, Q&A, knowledge base, or helpdesk history.
- Retrieve. Hybrid search and retrieval (dense embeddings + BM25) pulls candidate products and variants from your shopping catalog.
- Filter and rank. Variants are filtered by availability, structured attributes (size, width, currency, locale), and price.
- Compose. The assistant writes the answer grounded in retrieved rows and renders product cards.
- Refuse if needed. If no data supports the answer, the agent defers or escalates rather than guessing. Cart actions, upsells, and product suggestions from your AI agent all rely on the same catalog source. The best ai conversational experience still depends on what the store catalog contains.
Every step reads from your catalog. Every step degrades when a field is missing. For a deeper look at this retrieval architecture, see our Agentic RAG post.
Where Product Data Gaps Create Silent Failures
Bad catalog data rarely produces an obvious wrong answer. It produces failures that are hard to spot because nothing visibly breaks:
- Silent disqualification. A variant missing a width attribute simply isn't returned for "wide." The shopper sees fewer matches, not an error. Visual search, browsing, and conversational shopping experiences all suffer the same way when structured data is thin. Retailers lose the sale without knowing why.
- Right product, wrong variant. Alhena's engineering team discovered the assistant was returning sample-size variants on Paula's Choice routines because variant attributes didn't disambiguate full-size from sample. The fix was upstream, in the catalog data, not in the AI.
- Refusal that looks like ignorance. When no source data supports a claim, Alhena defers by design. To the customer, that reads as "the bot doesn't know." In reality, the catalog doesn't say. Reviews and Q&A aggregates (average rating, sentiment, common topics) are what let chatbots and chat-based assistants handle answering questions like "does this run small?" Without that data, it correctly refuses, but escalations rise.
- Confidently bland answers. Generic descriptions produce generic embeddings, and the assistant writes generic copy back. Accuracy is fine. Relevance is poor. Product discovery suffers.
You can trace each of these failures using Alhena's Conversation Debugger, which shows exactly which sources fed each response. For a detailed breakdown of which specific fields matter most and why, our post on product data fields for AI recommendations covers the full list.
What Alhena Does (and Doesn't Do) With Your Data
Alhena ingests catalog data through platform-specific connectors for Shopify, WooCommerce, Magento, and Salesforce Commerce Cloud. From that raw data, an AI-powered LLM-based attribute extractor builds structured fields against a schema. When a field can't be determined, it writes "N/A," not a guess. Alhena also builds a per-merchant taxonomy and aggregates reviews and Q&A into summaries the AI assistant in your store can cite. This contextual data layer is what turns a generic chatbot into an agentic, real time personalization engine that supports the full buying journey with tailored suggestions. For a deeper look at inventory accuracy, see how how Alhena keeps variant-level stock data fresh in real time.
What Alhena doesn't do: backfill missing attributes from imagination. If your feed doesn't say "machine washable," the assistant won't say it either. There's no cross-retailer truth-checking. And Alhena doesn't replace your PIM. The ai-driven product discovery layer for your conversational store stays grounded in your actual data. Retailers get what shoppers need only if the catalog delivers it. If you want more accurate answers, the fix is upstream, in the catalog. For guidance on keeping that data accurate over time, see AI Knowledge Base Ops.
Start With Your Catalog, Not Your Prompt
Most ecommerce merchants spend their first week after deployment tuning prompts and tone. That work matters, but it won't fix answers that fail because the source data is thin. Personalized recommendations, shopping guidance, and smart upsells all depend on the catalog. Shopping assistants serve customers across every channel, and every channel reads the same catalog.
Run a few test conversations with your AI-powered shopping assistant in the Shopping Assistant and trace each answer back to its source. Your team gets full visibility into what the assistant can and can't answer. Where you find gaps, fix the catalog. Shoppers expect real time, accurate answers. The agent can deliver better matching results the same day.
Ready to see how your catalog performs with an AI assistant? Book a demo with Alhena AI or start for free with 25 conversations.

Frequently Asked Questions
Why does product data quality matter for AI shopping assistants?
AI shopping assistants retrieve answers directly from your catalog data. They don't generate product knowledge independently. If attributes like size, price, or description are missing or thin, AI-powered shopping assistants either return wrong results, fewer results, or refuses to answer. Data quality sets the accuracy ceiling. Even the best ai shopping assistant can only match what your catalog provides.
What product data fields have the biggest impact on AI accuracy?
Six data points matter most: title and description (for search embeddings), structured variant attributes (for filtering), price/currency/locale links (for product cards), taxonomy (for category reasoning), reviews and Q&A (for subjective questions), and stock status (for availability). Missing any of these creates silent failures.
Does Alhena AI fix bad product data automatically?
Alhena extracts structured attributes from your raw catalog data using an LLM, but it doesn't invent missing information. If your feed doesn't include a field like "machine washable," the assistant won't claim it. Fields that can't be determined are marked as N/A, not guessed.
How can I tell if my catalog data is causing AI accuracy issues?
Use Alhena's Conversation Debugger, which shows exactly which data sources fed each AI response. When shoppers see refusals, wrong variants, or generic search results from the ai agent in your store, trace them back to the source rows. In most cases, the fix is in the catalog, not the prompt. Real time conversational shoppers deserve accurate responses.
What ecommerce platforms does Alhena AI integrate with for catalog data?
Alhena has dedicated catalog connectors for Shopify, WooCommerce, Magento, and Salesforce Commerce Cloud. Each integration connector ingests product data, variants, pricing, reviews, and Q&A specific to that platform's data model.
What happens when an AI shopping assistant can't find the answer in the catalog?
Alhena defers or escalates to a human agent rather than guessing. Even the best ai conversational assistant is designed this way. To the shopper it may look like the bot doesn't know, but it's actually the catalog that doesn't say. Filling those data gaps helps shoppers get answers and improves resolution rates.