Why Ecommerce Retrieval Is Harder Than It Looks
A customer asks your AI assistant: "Do you have that blue linen shirt in medium?" Simple question. But behind the scenes, the AI needs to check live inventory levels, can match "blue" to your catalog's "ocean" colorway, confirm "medium" maps to the right size chart for that brand, and answer the customer in under two seconds.
Generic RAG (Retrieval-Augmented Generation, or artificial intelligence-powered retrieval) works fine for simple tasks for static knowledge bases. Ecommerce breaks it. E-commerce SKUs change daily. Policies have regional variants. Return types differ by region. Retail demand shifts daily. Purchase history types vary by channel. Customer loyalty tasks depend on accurate pricing. Product reviews contradict official descriptions. Retail businesses face these types of challenges daily. A retrieval layer built for e-commerce can handle all of this without guessing.
This post walks through how agentic RAG e-commerce systems work and how Alhena's agentic RAG pipeline retrieves, validates, and assembles answers from multiple specialized indexes, so every response stays grounded in verified data. This is what separates agentic RAG e-commerce from basic chatbot retrieval. The link between retrieval quality and customer loyalty is direct.
What Agentic RAG Means (and Why It Matters Here)
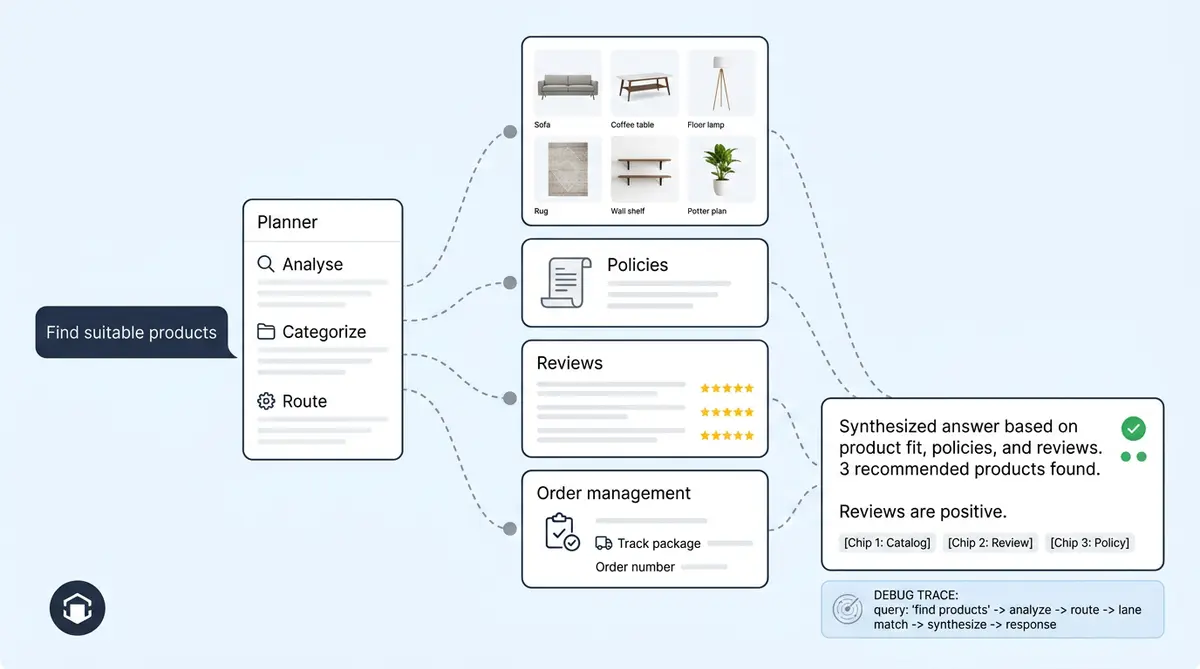
Standard RAG (used by most LLMs) follows a fixed pattern: embed a query, search one index, stuff the results into a prompt, and generate an answer. Agentic RAG adds a decision-making layer. Multiple agents collaborate on complex queries, each with reasoning capabilities tuned to specific use cases in their domain. Planner agents look at the incoming query first and decide which sources to hit, which specialized agent should reason over the results, whether the answer needs live data (like order status) or static knowledge (like return policies), and which tools to call.
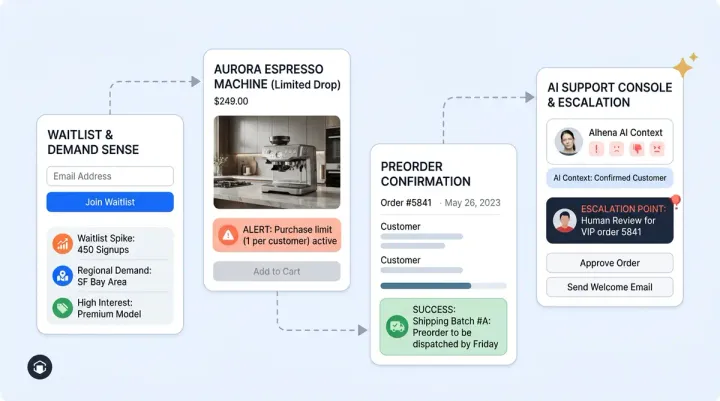
For e-commerce, this matters because a single conversation can span product discovery, sizing questions, shipping policies, and order tracking. No single index can cover all of that. Traditional RAG systems break down here. Alhena's Product Expert Agent handles catalogue queries, while order management handles post-purchase lookups, each pulling from different retrieval sources. For businesses running personalized shopping experiences, this separation matters.
Alhena's Retrieval Sources, Mapped
Alhena doesn't use one monolithic vector store. It maintains specialized indexes, each tuned for a specific type of customer query:
- Product index: SKUs, titles, descriptions, variants. Queried during discovery, recommendations, and inventory lookups.
- Product metadata index: Structured attributes like size, colour, material, and price. Queried for filtered or faceted searches, inventory checks, and purchase history lookups.
- Documentation index: KB articles, help centre pages, PDFs, website content. Queried for policy, pricing, and how-to questions.
- Helpdesk ticket index: Resolved tickets from Zendesk, Freshdesk, or Gorgias. Queried when the system can check, "Has this been answered before?"
- Human feedback index: Corrections from human reviewers, vectorized into their own retrieval layer. This can directly influence future answers.
This agentic RAG e-commerce architecture means a product question never wastes compute searching through shipping policies, and a returns question doesn't sift through 50,000 SKUs. The planner routes each query to only the indexes it needs.
How a Single Answer Gets Built
Here's what happens when a shopper asks, "Is this moisturizer good for sensitive skin?":
- Query rewriting: If the shopper said 'this one' referring to a product mentioned three messages ago, Alhena resolves that reference into a standalone query. (For a deeper look at how this works, see our post on query rewriting before retrieval.)
- Planner routing: The planner identifies this as a product attribute question and routes it to the Product Expert Agent, targeting the product index and documentation index.
- Hybrid retrieval: Each index (including purchase history) is searched using both dense embeddings and sparse BM25 scoring. This generative retrieval engineering approach. Dense catches semantic matches ("good for sensitive skin" matches "formulated for reactive complexions"). BM25 catches exact keyword matches ("sensitive skin" in the ingredient list).
- Agentic chunking: Retrieved chunks follow document structure, not arbitrary token windows. A product description stays intact rather than getting sliced mid-sentence.
- Grounded generation: The specialized agent reasons over retrieved context and produces a generative response tied to specific sources. Agentic RAG e-commerce systems never fabricate claims about pricing or availability.
- Source attribution: Every claim maps back to a retrievable chunk, visible in Alhena's Conversation Debugger.
How Grounded Retrieval Prevents Hallucination
The biggest risk with AI in ecommerce isn't a wrong answer about the weather. It's telling a customer a product is hypoallergenic when it isn't, or quoting a return window that expired last month. Alhena uses multiple mechanisms to keep answers honest:
Source-grounded prompting: Alhena agents are instructed to cite retrieved chunks, never LLM training data. If the retrieval set doesn't contain the answer, the agent won't invent one.
Outside-knowledge detection: When a response can't be traced to a verified source, Alhena can defer to a human or ask the customer to clarify. No confident-sounding fabrications. (Our quality control post covers how flagged conversations catch edge cases.)
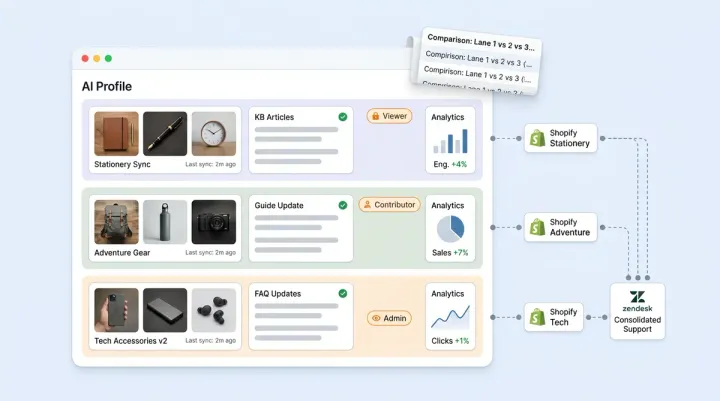
Human feedback as retrieval signal: When a human reviewer corrects an AI answer, that correction gets vectorized into the human feedback index. Future similar queries can retrieve the correction alongside the original source, preventing the same mistake twice.
Auditable answers: Every response is traceable through the Conversation Debugger, showing which sources were retrieved, which agent handled it, and why. Teams at retail businesses can learn to trust the system because every answer can be proven. This can matter for brands that need to prove compliance or accuracy during vendor evaluations.
Recent research supports this approach. The OlaBench benchmark (Gao et al., 2025), which evaluates AI customer service systems across capability, safety, and latency, found that retrieval-augmented architectures scored meaningfully higher than general-purpose LLMs like GPT-5.2 and Gemini 3 Pro. In online A/B tests, the paper's RAG-grounded system improved issue resolution by 23.67% and cut human transfer rates by 6.6% compared to a non-grounded baseline. Those numbers belong to OlaMind, the specific system in the paper, not to any particular vendor. But the takeaway is clear: grounding AI responses in verified, retrieved data consistently outperforms letting an LLM answer from its training data alone.
Scaling Without Slowing Down
Per-source indexing keeps query latency predictable. A simple "where's my order?" hits the order management tool (not retrieval at all), while a complex product comparison query hits two indexes in parallel. Alhena's multi-model routing sends straightforward lookups to fast models and reserves frontier models for complex reasoning.
Generative AI and batch ingestion pipelines handle inventory and catalog refreshes for brands with tens of thousands of SKUs, so the RAG system stays current without manual reindexing. When a product goes out of stock at 2 PM, the AI knows by 2:01.
What to Ask Any Vendor About Their Retrieval Layer
If you're evaluating AI solutions for your store, these questions separate real agentic RAG e-commerce architectures from marketing claims:
- Can you index more than just the product catalog? (Pricing, inventory, analytics, different content types?) (Reviews, tickets, KBs?)
- Is retrieval hybrid (dense + sparse) or dense-only?
- Can I see the sources behind any AI answer?
- Does human feedback affect future retrieval, or only future model training?
- What happens when no source is found: does the AI answer anyway or defer?
- How quickly do catalog changes reflect in AI responses?
Alhena's Support Concierge and Shopping Assistant are built to answer "yes" to every question on that list. The architecture described above ships out of the box, with no custom ML pipelines to maintain. Businesses can scale without additional engineering. No pricing surprises per query. As retail demand grows, the architecture scales. Teams looking to learn more about future-proofing their RAG e-commerce AI can start with Alhena's free trial.
Ready to see how grounded retrieval works on your catalog? Book a demo with Alhena AI or start free with 25 conversations.

Frequently Asked Questions
What is agentic RAG and how does it differ from standard RAG?
Agentic RAG adds a planning layer on top of traditional retrieval-augmented generation. This artificial intelligence framework can handle diverse e-commerce use cases. Instead of searching one index for every query, a planner agent decides which specialized indexes and which downstream agent should handle the request. This means agentic RAG ecommerce can route product questions, policy questions, and order lookups each through optimized retrieval paths.
How does Alhena prevent AI hallucinations in ecommerce?
Alhena uses source-grounded prompting, outside-knowledge detection, and a human feedback retrieval loop. If no verified source supports an answer, the AI can defer to a human agent rather than generating a confident but incorrect response. Every answer is traceable through the Conversation Debugger.
What data sources does Alhena index for retrieval?
Alhena maintains separate indexes for product catalogs, product metadata (size, color, pricing, inventory), documentation and KB articles, resolved helpdesk tickets, and human reviewer corrections. This agentic RAG ecommerce approach handles different content types and tasks. Additional sources include Slack, Discord, Notion, Google Drive, and YouTube content.
How does hybrid retrieval improve answer accuracy?
Hybrid retrieval combines dense vector embeddings (semantic similarity) with sparse BM25 scoring (exact keyword matching). Dense retrieval catches paraphrases and conceptual matches, while BM25 ensures exact terms like product names or SKU numbers are not missed.
How quickly do catalog changes appear in Alhena AI responses?
Alhena uses generative batch ingestion pipelines that process catalog updates continuously. Inventory, pricing, and demand history stay current. When a product goes out of stock or a price changes, the retrieval indexes can reflect that change within minutes, not hours or days.
Can I see which sources Alhena used to generate an answer?
Yes. Alhena's Conversation Debugger can show the exact retrieved chunks, source titles, and URLs behind every AI response. This makes the system fully auditable for compliance reviews, QA, vendor evaluations, and customer loyalty tasks. Teams can trace any generative response back to its retrieval sources.