A vendor says their AI chatbot is "north of 90 per cent accurate". Another claims a "92% resolution rate". A third advertises "85% deflection". All three numbers sound impressive, but they're measuring completely different metrics. And none of them tell you whether the chatbot will actually work for your enterprise e-commerce business.
This article gives you five questions every customer-facing team should ask before you trust any vendor's accuracy headline. If you need a refresher on what containment, deflection, and resolution actually mean, our containment vs. deflection rate breakdown covers the definitions in detail.
Why a Single Accuracy Number Is Meaningless
"Accuracy" isn't a standardized term in the generative AI and conversational AI industry. One vendor might mean per-message factual correctness. Another might mean the percentage of conversations that ended without a human stepping in, which is closer to containment than accuracy. A third might be counting only the conversations their bot chose to handle, quietly excluding every question it dodged.
The result: two vendors can both claim "90% accuracy" while delivering wildly different customer experiences. One might be getting 90% of responses right but confidently hallucinating on the other 10%. The other might be refusing to answer 40% of questions and getting 90% of those correct.
Both are "90% accurate". Neither number, on its own, tells you what your business needs to know.
Five Chatbot Accuracy Questions to Ask Any Vendor
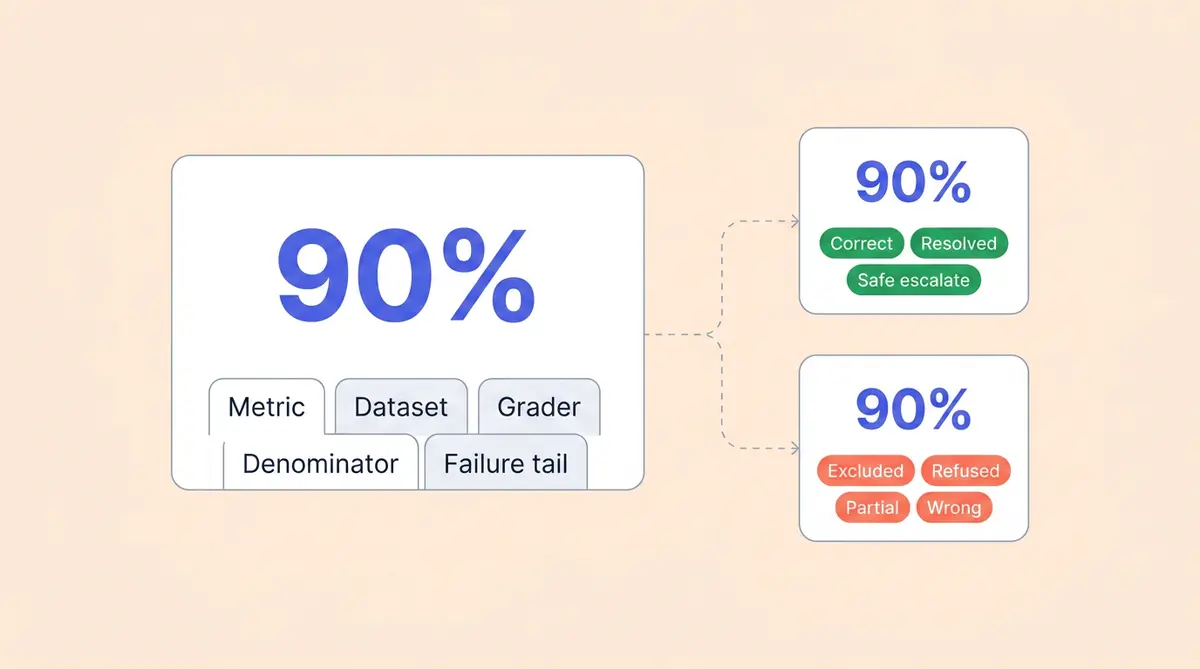
1. What exactly are you measuring?
Ask the vendor to define their customer-facing metric precisely. Is it per-message factual correctness against a ground truth? Per-conversation resolution (the customer's issue was fully handled)? Or simple containment (no human handoff happened, regardless of whether the user was satisfied)?
Each of these is a legitimate metric, but they produce very different numbers for the same set of conversations. Our guide to AI support KPIs explains how AHT, FCR, containment, and CSAT interact.
2. What dataset produced this number?
Was it the vendor's internal test set (likely curated to show strength), your real user traffic, or a synthetic benchmark? Industry benchmarks? Sample size matters too, and one MIT study suggests larger samples produce more reliable scores. A "95% accuracy" claim based on 200 hand-picked questions is very different from one validated against 10,000 real-world interactions across all intent types, conversational flows, and platforms.
3. Who did the grading?
Self-graded accuracy is the most common and least reliable methodology. If the vendor's own team decided what counts as "correct", the number is marketing, not measurement. Ask whether an independent team, a structured rubric with inter-rater agreement and transparent information sharing, or an LLM-as-judge approach was used. Understanding the grading method matters as much as the score.
4. What's in the denominator?
This is where numbers get quietly inflated. If out-of-scope questions, abusive messages, or "I don't know" responses are excluded from the denominator, the accuracy rate climbs without the bot actually getting better. A bot that refuses to handle 30% of questions and gets 90% of the rest right has a real accuracy closer to 63%.
5. What does the other 10% look like?
The failure tail is where the risk lives. "10% inaccurate" could mean the bot politely said "let me connect you to a human" (safe) or confidently told a customer the wrong return policy, processing a refund they weren't entitled to (expensive). Ask the vendor to break down their failures into categories: safe refusals, partial answers, and confidently wrong answers. The mix matters more than the headline.
Failure Modes That Chatbot Accuracy Headlines Hide
Even after you've asked those five questions, watch for three patterns that a single accuracy metric can't capture:
- Long-tail intent failures. Average accuracy might be 92%, but the bottom 10% of intent categories (complex returns, order management and account management edge cases, and promo stacking questions) could be at 40%. Those are often the conversations that drive the most churn.
- Drift over time. Day-one accuracy is a snapshot. Catalogs change, policies change, and new product lines launch. Without continuous learning, accuracy degrades every week. A recent study on AI drift reinforces this. Our post on self-improving AI architecture covers how this works in practice.
- Channel skew. A bot tested on web chat might score 90%, but the same model handling email, WhatsApp, or voice could perform very differently. One number averages away those gaps.
How Alhena Approaches Chatbot Accuracy Differently
Alhena AI doesn't publish a single headline accuracy number, and that's intentional. Instead, Alhena gives you the tools to have your team run their own evaluation on your own data.
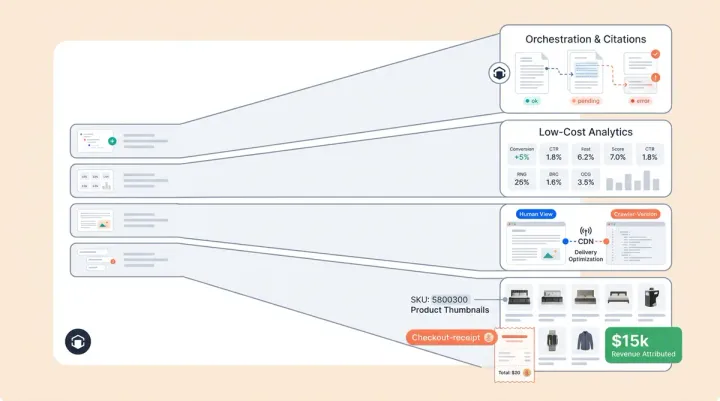
Resolution rate in your dashboard. Alhena's Agent Performance Analytics shows resolution rate defined as conversations fully resolved and closed by the AI without human transfer, calculated on your real-world customer traffic, available directly in your dashboard, not a curated sample.
Smart Flagging for the failure tail. Rather than burying the 10%, Alhena's flagged conversations system automatically surfaces responses that show outside-knowledge statements automatically surfaces responses that show outside-knowledge statements, low confidence, customer frustration, customer complaint patterns, compliance issues, or policy-sensitive topics. You see the failures before your users feel them.
Source tracing for every response. Every answer links back to the specific product catalog data, giving you full traceability and actionable insights, policy document, FAQ entry, or product integration that generated it. If an answer isn't grounded in your verified data, it doesn't get served. That's what hallucination-free means in practice.
Guideline regression testing. Before any tuning change goes live, Alhena runs side-by-side tests comparing new responses against your existing question set. You see what changed and approve it before customers experience it. For the full testing framework, see our 3-week stress-test guide.
Build Your Own Chatbot Accuracy Evaluation
The best way to cut through chatbot accuracy marketing is to run your own evaluation. We've published detailed frameworks for this: our 10-question AI agent evaluation checklist covers what to ask, and our low-risk AI pilot guide walks through the step-by-step process.
The short version: take 200 to 500 real past tickets, stratified by intent and complexity. Have two independent expert graders score the AI's responses and the information it provides on factual correctness, source grounding, information quality, and user feedback signals. Set your acceptance bar before you test, not after. And re-evaluate monthly to catch drift.
If a vendor won't let you run this kind of audit on your own data before you sign, that tells you more than any accuracy number ever could.
Ready to see how Alhena AI performs on your actual customer questions? Book a demo or start free with 25 conversations and run your own assessment.

Frequently Asked Questions
What is the difference between chatbot accuracy and resolution rate?
Accuracy measures whether individual AI responses are factually correct against ground truth. Resolution rate measures whether an entire conversation was handled without human transfer. A bot can have high accuracy on answered questions but low resolution rate if it escalates frequently.
How do I benchmark an AI chatbot before buying?
Build a golden test set of 200 to 500 real past tickets, stratified by intent and complexity. Have two independent graders score factual correctness and source grounding. Set your acceptance bar before testing, not after. Re-test monthly to catch performance drift.
Why do AI chatbot vendors report different accuracy metrics?
There is no industry standard for chatbot accuracy. Vendors choose whichever metric produces the best-looking number for their product. Some report per-message correctness, others report conversation-level containment, and others exclude out-of-scope questions entirely. Always ask exactly what is being measured.
What is a good chatbot accuracy rate for ecommerce?
It depends on the metric. For factual correctness per response, 90% or above on a blind evaluation set is a reasonable target. For conversation resolution rate, 60 to 80% is typical for a well-tuned ecommerce bot. The hallucination rate should stay below 2%.
How does Alhena AI measure chatbot accuracy?
Alhena exposes resolution rate in its Agent Performance Analytics dashboard, calculated on your live traffic. Smart Flagging surfaces low-confidence or ungrounded responses automatically. Every response is traceable to its source data, so you can verify accuracy yourself rather than relying on a vendor-reported number.
What is chatbot hallucination rate and why does it matter?
Hallucination rate is the percentage of AI responses that contain statements not supported by any source material. A confidently wrong answer costs far more than a simple refusal. Alhena prevents ungrounded responses by tying every answer to verified product catalog, product descriptions, or policy data.