Picking the wrong AI agent costs more than a wasted subscription. It means hallucinated product recommendations, dropped conversations, and customers who don't come back. Most ecommerce teams run their ai agent evaluation the same way they'd score any SaaS tool: check features, compare prices, move on. That process wasn't designed for software that talks to your customers.
For a strategic lens that goes beyond feature scoring, see our 3-bucket framework for evaluating AI ecommerce vendors, which maps vendors across shopping, support, and AI visibility buckets.
AI agents reason, generate language, and interact with shoppers in real time. A bad pick doesn't just waste budget. It actively damages your brand through wrong answers, off-target suggestions, and frustrated buyers. This ai agent evaluation checklist gives you ten questions that separate a strong vendor from an expensive mistake, whether you're comparing an AI chatbot for ecommerce or a full-stack AI shopping assistant.
Why Most AI Agent Evaluations Miss What Matters
The typical vendor evaluation process was built for static software. You check a box for each feature, compare pricing tiers, and pick the one that covers the most ground. That works fine for email platforms or project management tools. It falls apart for AI agents.
AI agents are different because their output is non-deterministic. Two agents with identical feature lists can produce wildly different results. One might recommend the perfect product for a vague request. The other might hallucinate a product that doesn't exist in your catalog.
The cost of getting this wrong is real. Bad product recommendations kill conversion rates. Hallucinated answers erode customer trust. And an agent that can't handle the full shopping journey just creates more handoff friction, not less. Teams that evaluate ai agent evaluation metrics like accuracy, reasoning quality, and commerce context consistently outperform those that stop at the feature checklist.
What you need is a structured ai agent evaluation framework designed specifically for ecommerce. One that tests how the agent actually performs with your products, your customers, and your workflows. That's what this checklist provides.
The 10-Point AI Agent Evaluation Framework
Use these 10 questions as your scoring framework when evaluating any ecommerce AI agent. Each question includes a practical test you can run, red flags to watch for, and what a strong answer looks like.
1. Does the agent understand shopping intent, not just keywords?
Test: Ask a vague question like "something warm for a mountain trip." Does the agent ask clarifying questions about activity type, budget, or climate? Or does it dump every jacket and blanket in your catalog?
Red flag: Keyword matching disguised as AI. If the agent just searches for "warm" and "mountain" in product titles, it's a glorified search bar, not an intelligent agent.
What good looks like: The agent asks contextual follow-up questions. It narrows options based on the conversation, not just the query. It understands that "something warm for a mountain trip" probably means outerwear or layering pieces, not heated blankets. The best AI shopping assistants treat every query as a conversation, not a search.
2. Is the AI grounded in your actual product data?
Test: Ask about a product that's out of stock or recently discontinued. Does the agent recommend it anyway? Ask for a product with specific specs. Does it make up details that don't exist?
Red flag: Generic responses that aren't tied to your live catalog. If the agent gives plausible-sounding answers that don't match your actual inventory, you've got a hallucination problem.
What good looks like: Real-time catalog sync with hallucination-free answers. The agent only recommends products that are actually available and quotes accurate specs, pricing, and availability. Accuracy isn't optional. As we covered in our deep dive on hallucination-free AI for ecommerce, even a 2% hallucination rate compounds into thousands of bad customer interactions per month.
3. Can it handle the full shopping journey, not just one step?
Test: Start with product discovery ("I need running shoes for wide feet"), then ask a support question ("what's your return policy on shoes?"), then try to check out. Does the agent maintain context throughout, or does it break when you switch modes?
Red flag: Separate bots for support versus sales. If discovery is one system and support is another, your customer gets bounced between tools, losing context every time.
What good looks like: A single agent that handles browse, buy, and post-purchase in one continuous conversation. An AI support concierge should know what a customer was just shopping for when they ask a support question. No handoffs, no repeated information.
4. Does it work across channels you actually use?
Test: Try the agent on your website, then test it on Instagram DM, WhatsApp, and email. Is the experience consistent? Does it have the same product knowledge across every channel?
Red flag: Web-only deployment or requires separate setup, training, and maintenance per channel. If adding WhatsApp means a whole new implementation, the vendor isn't built for modern commerce.
Once you've chosen an agent, our guide on training and customizing AI agents for ecommerce covers the 8 best practices for getting it right.
What good looks like: Omnichannel from day one. Same agent, same knowledge, same quality across every touchpoint. AI social commerce should work identically whether the customer reaches you through your site, Instagram, or a WhatsApp message. DTC brands especially need this, since customers expect consistent experiences wherever they engage.
5. Can you measure revenue impact, not just deflection?
Test: Ask to see revenue attribution reports. Can the vendor trace a specific conversation to a completed sale? Can you see average order value uplift for AI-assisted sessions versus non-assisted ones?
Red flag: The vendor only tracks tickets deflected or CSAT scores. Deflection is a cost metric, not a revenue metric. If that's all they measure, the agent is positioned as a cost center, not a growth driver.
What good looks like: Conversion rate tracking, AOV uplift measurement, and revenue per conversation metrics. You should be able to see exactly how much revenue the agent influenced. The real benefits of AI agents show up in the revenue column, not just the support cost column.
6. How fast can you deploy without dev resources?
Test: Ask the vendor for a typical implementation timeline. Find out what's required from your side. Do you need engineers to set up integrations? How long before the agent is live with real customers?
Red flag: "6-8 week implementation with a dedicated dev team." If deployment requires months of engineering work, you'll burn through budget before seeing any results. And you'll be locked into a long commitment before knowing if it works.
What good looks like: Under 48 hours to go live, no code required. The agent should ingest your product catalog automatically and start handling conversations within days, not months. This is one of the common mistakes brands make when implementing AI agents: overcomplicating the rollout.
7. Does the agent match your brand voice?
Test: Compare agent responses side-by-side with your brand guidelines. Does the agent sound like your brand or like a generic chatbot? Try asking the same question to the agent and to your best human support rep. How close is the match?
Red flag: Generic, robotic tone that sounds the same across all merchants. If a luxury skincare brand and a budget electronics store get identical-sounding responses, there's no real brand customization happening.
What good looks like: Customizable tone, vocabulary, and personality. The agent should adapt to your brand's style, whether that's casual and fun, professional and polished, or technical and precise. You should be able to adjust this without filing a support ticket.
8. What happens when the AI doesn't know the answer?
Test: Ask something genuinely edge-case, a question about a product combination you've never been asked before, or a policy question that's buried in your terms. Does the agent fabricate an answer, or does it recognize the gap?
Red flag: Confident wrong answers. Hallucinations dressed up with polished language are worse than saying "I don't know." A customer who acts on wrong information becomes a return, a complaint, or a lost customer for life.
What good looks like: Graceful escalation to human agents with full conversation context. AI agent assist should pass the customer to a human smoothly, with every detail of the conversation included so the customer never has to repeat themselves.
9. Does it integrate with your existing stack?
Test: Check for native integrations with your commerce platform, helpdesk, CRM, and order management system. Don't just ask if they integrate. Ask how. Is it a native connector or custom API work?
Red flag: Requires custom API development for basic connections. If connecting to Shopify or Zendesk needs weeks of engineering, the platform wasn't built for ecommerce.
What good looks like: Native connectors for Shopify, Shopify Plus, WooCommerce, Magento, BigCommerce, Zendesk, Gorgias, Freshdesk, and more. Ecommerce AI solutions should plug into your stack within hours, not weeks.
10. Can you quantify the ROI before committing?
Test: Ask the vendor for a projected ROI calculation based on your actual traffic volume, ticket count, and average order value. Can they give you a real number, or just vague promises?
Red flag: "Results vary" with no modeling capability. If a vendor can't project ROI with your real data, they either don't have confidence in their product or don't have the analytics to back it up.
What good looks like: An ROI calculator that takes your inputs and produces concrete projections for revenue lift, cost savings, and payback period. You should know the expected return before signing anything.
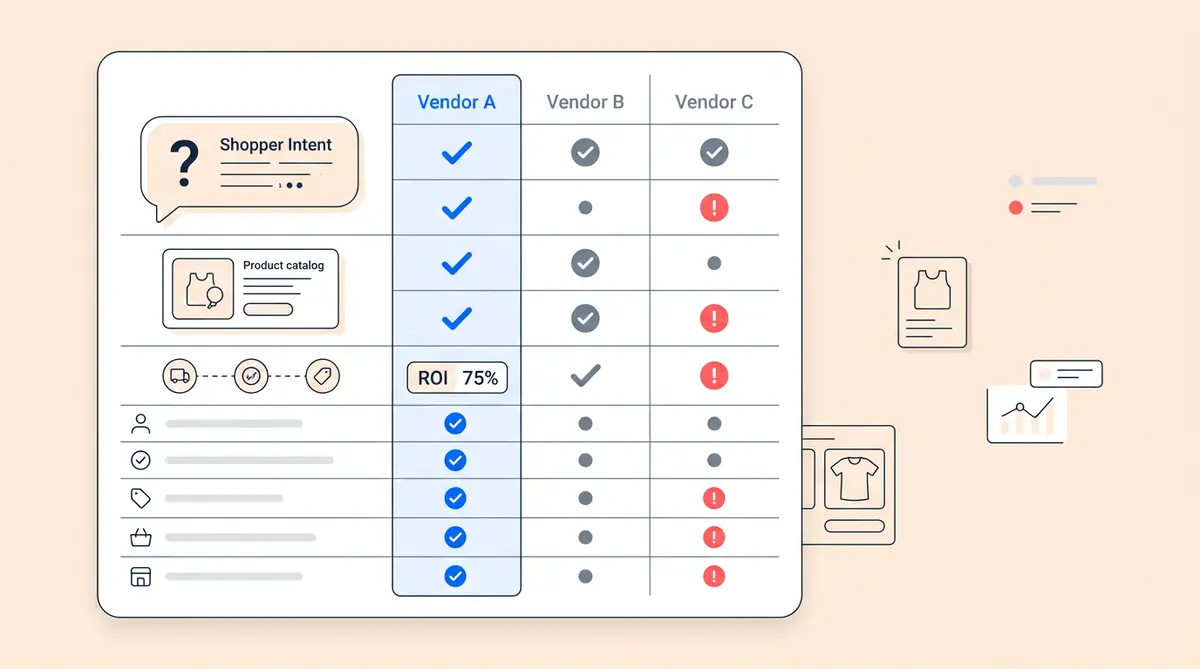
AI Agent Evaluation Scorecard: How to Rate Vendors 1 to 5
Now that you have the 10 questions, turn them into a scoring system. Rate each question on a 1-5 scale for every vendor you evaluate:
- 5 - Excellent: Vendor exceeds expectations with clear evidence
- 4 - Strong: Meets the criteria with minor gaps
- 3 - Adequate: Partially meets criteria but has notable limitations
- 2 - Weak: Significant gaps that would require workarounds
- 1 - Fail: Doesn't meet the criteria at all
Score ranges for your ai agent evaluation:
- 40-50: Strong fit. Move to pilot phase with confidence.
- 30-39: Good with caveats. Identify the gaps and determine if the vendor has a roadmap to close them.
- Below 30: Keep looking. Too many gaps to justify the risk.
Weight the questions based on your priorities. Omnichannel matters more for DTC brands with active social selling. Revenue attribution matters more for high-traffic stores. Accuracy is non-negotiable for everyone.
How Alhena AI Performs on This Evaluation Checklist
We built Alhena AI specifically for ecommerce, so we designed it to score well on exactly these criteria. Here's how Alhena addresses each of the 10 questions, with proof points from real customers.
1. Shopping intent understanding: Alhena's AI doesn't keyword-match. It uses contextual reasoning to understand what customers actually want, asking follow-up questions to narrow from thousands of products to the right three or four options. Tatcha saw 3x conversion rates after switching to Alhena, largely because the AI guides shoppers through complex skincare routines instead of dumping product lists.
2. Grounded in real product data: Alhena syncs with your live catalog in real time. It won't recommend out-of-stock items or fabricate product specs. Every response is grounded in your actual data, not general training knowledge.
3. Full shopping journey: One agent handles discovery, support, and post-purchase. There's no handoff between a "sales bot" and a "support bot." The same conversation can move from "show me winter jackets" to "what's your return window?" without losing context.
4. Omnichannel: Alhena works across web chat, email, Instagram DM, WhatsApp, and more from a single deployment. Same product knowledge, same brand voice, every channel. No separate setup required.
5. Revenue attribution: Alhena tracks conversion rate, AOV uplift, and revenue per conversation. You can see exactly which AI-assisted conversations led to purchases and how much revenue the agent influenced.
6. Fast deployment: Most brands go live in under 48 hours with no engineering required. Alhena ingests your product catalog automatically and starts handling conversations immediately. Manawa dropped response times from 40 minutes to under 1 minute after deploying.
7. Brand voice: You configure Alhena's tone, vocabulary, and personality to match your brand. A luxury beauty brand sounds different from a casual outdoor retailer, and Alhena reflects that.
8. Graceful escalation: When Alhena doesn't know an answer, it escalates to a human with full conversation context. No hallucinations, no made-up answers. Puffy achieved 63% automated resolution while maintaining quality, meaning the other 37% gets clean handoffs to humans who have full context.
9. Native integrations: Shopify, Shopify Plus, WooCommerce, Magento, BigCommerce, Zendesk, Gorgias, Freshdesk, and more. All native connectors, no custom API work needed.
10. ROI projection: Alhena provides an ROI calculator that uses your traffic and ticket volume to project revenue impact before you commit. You see the numbers before you sign.
Five Evaluation Mistakes That Cost Ecommerce Teams Money
Even with a good checklist, teams still make predictable errors during vendor evaluation. Here are the five most common mistakes we see.
Evaluating based on the demo alone. Demos are scripted. The vendor controls the questions, the products, and the scenario. Always ask for a pilot with your real product data and real customer queries. A pilot exposes edge cases that demos hide.
Prioritizing price over revenue impact. A cheaper agent that converts at 1% costs you more than a premium agent that converts at 4%. Run the math on revenue impact, not just subscription cost. Use the ROI calculator approach from Question 10.
Ignoring accuracy in favor of speed. Fast responses don't matter if they're wrong. A customer who gets an instant but hallucinated answer is worse off than one who waits 30 seconds for the right one. Accuracy should be your first filter, not an afterthought.
Treating AI agents like chatbots. Chatbots follow decision trees. AI agents reason, adapt, and generate responses dynamically. If your evaluation criteria were built for chatbots (things like "number of predefined flows" or "decision tree depth"), you're measuring the wrong things entirely.
Not testing with real customer queries. Pull your top 50 customer questions from the last month. Run them through every vendor you're evaluating. The gap between demo performance and real-query performance will tell you everything you need to know.
Start Your AI Agent Evaluation Today
You now have a structured ai agent evaluation framework built for ecommerce. Use the 10-question checklist, score each vendor on the 1-5 scale, and let the data guide your decision.
If you want to see how Alhena AI performs against your checklist, there are a few ways to get started:
- Book a demo to see Alhena handle your real products and customer scenarios
- Start free with 25 conversations to test it yourself, no commitment required
- View pricing for full transparency on costs and what's included
The best ai agent evaluation isn't about who has the longest feature list. It's about who delivers accuracy, revenue impact, and a real customer experience for your specific store. Start with the right questions, and the right answer becomes obvious.
Pricing alignment is one of the most overlooked evaluation criteria. Our analysis of credit-based AI pricing and vendor incentive alignment explains why this matters for your contract decisions.

Alhena AI
Frequently Asked Questions
What questions should I ask when evaluating an AI agent for my online store?
Focus on ten areas: shopping intent understanding, product data accuracy, full-journey coverage, omnichannel support, revenue attribution, deployment speed, brand voice fit, escalation handling, stack integrations, and ROI projection. Alhena AI scores high across all ten because it was built specifically for ecommerce sales and support.
How do I tell if an AI chatbot actually drives sales or just deflects tickets?
Ask the vendor for conversion rate tracking, average order value uplift data, and revenue-per-conversation metrics. If they can only show ticket deflection numbers, the tool is built for cost cutting, not growth. Alhena AI tracks attributed revenue directly, with brands like Tatcha seeing 3x conversion rates and 11.4% of total site revenue from AI-assisted chats.
What is the biggest red flag when choosing an ecommerce AI agent?
Confident wrong answers. If the agent recommends products that are out of stock or fabricates specs, every bad response erodes customer trust. Alhena AI grounds every reply in your live catalog data, so it never recommends items you don't carry or invents details that aren't in your database.
How long does it take to set up and test an AI agent for ecommerce?
A proper evaluation takes two to four weeks: one week for demos and scoring, two weeks for a pilot with real products and customer queries, then a final week to analyze results. Alhena AI deploys in under 48 hours with no dev resources, so your pilot can start almost immediately.
Can I try an AI shopping assistant before signing a long-term contract?
You should always demand a trial before committing. Run your 50 most common customer questions through each vendor during the pilot. Alhena AI offers 25 free conversations so you can test with real shoppers, no credit card or annual contract required.
What AI agent evaluation metrics matter most for ecommerce stores?
Prioritize hallucination rate, conversion lift, average order value change, resolution rate, and response accuracy. Deflection rate alone tells you about cost savings but nothing about revenue. Alhena AI reports all of these through built-in revenue attribution analytics.
Does Alhena AI work with Shopify, WooCommerce, and popular helpdesks?
Yes. Alhena AI has native connectors for Shopify, Shopify Plus, WooCommerce, Magento, and BigCommerce on the commerce side, plus Zendesk, Gorgias, Freshdesk, Intercom, and more on the helpdesk side. No custom API work needed, and most integrations go live the same day.
How do I score and compare AI agent vendors using a checklist?
Rate each vendor on a 1 to 5 scale across the ten evaluation questions. A total score of 40 to 50 means strong candidate. Between 30 and 39, check roadmaps for gap closures. Below 30, keep looking. Weight questions based on your priorities, whether that is omnichannel reach, accuracy, or speed to deploy.
What makes Alhena AI different from general-purpose AI chatbots?
General chatbots handle Q&A but don't understand product catalogs, shopping intent, or purchase flows. Alhena AI is purpose-built for ecommerce with two specialized agents: a Product Expert that guides buying decisions and an Order Management Agent that handles post-purchase queries. It also populates carts and pre-fills checkout directly inside the conversation.