Every AI Hallucination Starts with a Documentation Problem
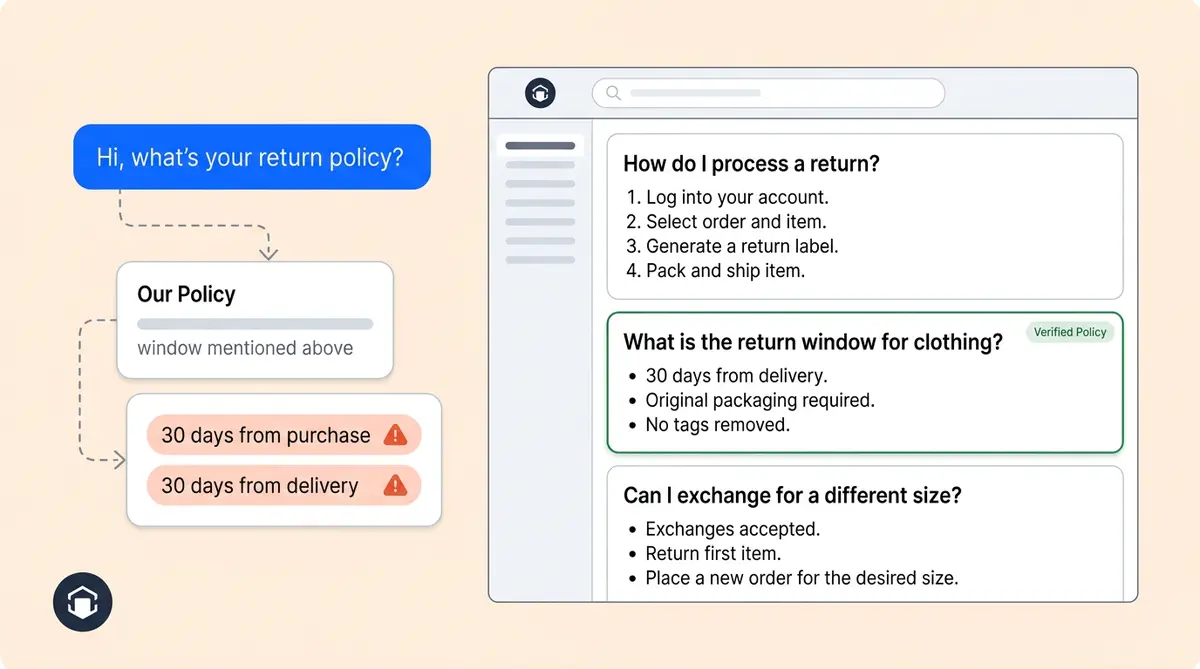
A customer asks your AI agent, "Can I return this after 30 days?" The agent pulls two chunks from your knowledge base. One says returns are accepted within 30 days of purchase. The other says 30 days from delivery. The agent picks one, sounds confident, and gives the wrong answer.
That's not a model failure. That's a customer service content failure. And no amount of prompt engineering, guardrails, or model upgrades can fix information that was never written clearly in the first place.
A good RAG platform (like Alhena AI) will normalize your content, strip navigation noise, convert HTML to Markdown, and chunk it intelligently. What it can't do is resolve the ambiguity you wrote into the source. That part is yours.
This guide covers the four authoring habits that most affect AI retrieval accuracy and what each one buys you.
Write Self-Contained Sections, Not Connected Narratives
RAG systems split your documents into chunks, typically a few hundred tokens each. At query time, they process a search and retrieve the most contextual chunks, not the full page. Your 3,000-word help article? The AI might only see paragraph four.
That means every section in your documents needs to stand on its own. If a paragraph says, "It must be unopened and returned within the window mentioned above," the AI has no idea what "it" is or what "window" means without the surrounding context.
What to do instead:
- Repeat the noun. "The product must be unopened" beats "It must be unopened."
- Restate conditions in every section that references them. Don't force the reader (or the AI) to scroll up.
- Avoid "as mentioned above" or "see section 3" references. They break when content is retrieved out of order.
If you want to understand how Alhena's chunking system handles this on the platform side, our agentic chunking deep-dive covers the technical mechanics.
Use Headings That Match How Customers Ask Questions
Headers provide contextual signals in a RAG system. They tell humans where to look, and they tell retrieval systems what a chunk is about. Many chunkers split on headings. Many embedding models concentrate meaning around them.
A heading like "Our Policy" followed by 800 words covering returns, refunds, exchanges, store credit, and gift cards is retrieval poison. The embedding for that chunk represents everything and nothing at the same time.
Better approach:
- One topic per heading. If you need "and" in your header, split it into two sections.
- Match the language your customer service team hears daily. "Returns After 30 Days" beats "Extended Resolution Window".
- Keep your H1, H2, and H3 hierarchy clean. Don't skip levels for styling purposes.
- Front-load the answer in the first sentence under each heading. Retrieval systems often weight the top of a chunk more heavily.
Decorative headers like "We're Here for You!" or "Welcome!" pollute your retrieval index with feel-good chunks that match nothing useful.
Eliminate Contradictions and Implicit Context
This is the highest-leverage fix only you, the author, can make. For organizations running AI-powered customer service, ambiguity is the silent killer of accuracy. The model isn't inventing answers. It's faithfully retrieving two contradictory sources and stitching them together.
The most common offenders:
- Implicit context. "We refund within 30 days. " From purchase? From delivery? From the refund request?
- Hidden conditionals. "Most items are returnable" without the exceptions list on the same page.
- Stale duplicates. A 2022 page says "free shipping over $75" while a 2024 page says "$50". Both get indexed.
- Marketing voice in policy docs. "We've got your back!" retrieves nothing actionable.
The author's fix:
- One source of truth per fact. If shipping thresholds appear in five places, four should link to the canonical page, not restate the number.
- Make conditions explicit. Use structured tables or bullet lists: "Eligible: unopened, within 30 days of delivery, with receipt."
- Date your policy pages. "Last updated: March 2026" is both a retrieval signal and an internal hygiene signal.
Alhena's Smart Flagging system catches many of these contradictions after ingestion by surfacing low-confidence answers for human review. But fixing the source documents is always faster than fixing the output.
Structure for Machines Without Losing the Human Reader
You don't need to write like a robot to provide well-structured content that AI agents can use. You need to write clearly, specifically, and without assuming your reader has seen the rest of the page.
A quick formatting checklist:
- Use semantic HTML or Markdown. Proper
<h2>tags and<table>elements beat styled divs that look like headings but aren't. - Tables over prose for enumerable facts. Shipping rates and return windows survive chunking better as structured data.
- Keep related facts together. Don't separate a rule from its exceptions by 500 words of context.
- Short paragraphs. Two to four sentences. Each one should carry a distinct point.
If your knowledge base lives in a help-center platform, keep articles clean. Organizations should avoid heavy templating, "related articles" carousels baked into the content body, and JavaScript-rendered elements that won't survive extraction.
A 15-Minute Knowledge Base Audit You Can Run This Week
Your team doesn't need a multi-sprint process to improve retrieval accuracy. Start with your customer service documents:
- Pull your top 10 support questions. For each, can you find a single page section that answers it completely? This process reveals the biggest gaps.
- Search for any fact that appears in 3+ places. Pick one canonical source. Convert the rest to links.
- Find every heading with "and" or "&" in it. Split those sections.
- Check "Last updated" dates. Anything older than 12 months gets re-read and verified.
- Review your AI agent's flagged conversations. Each low-confidence flag is a customer service content-debt ticket pointing your team to exactly what needs rewriting. It’s the fastest automation feedback loop you’ll find.
For ongoing maintenance after this initial pass, our guide on AI knowledge base ops covers the weekly cadence that keeps your AI accurate as your catalog changes.
Good Source Data Is the Ceiling on AI Accuracy
No model upgrade, prompt trick, or retrieval algorithm can recover information that wasn't clearly documented. The best RAG systems in the world, Alhena's Product Expert Agent included, are only as good as the content they're grounded in.
Alhena handles the heavy lifting in your customer service process: HTML-to-Markdown conversion, semantic chunking, grounded retrieval, and continuous learning from flagged conversations. But the clarity of your documentation, the absence of contradictions, and the structure of your headings? That's the ceiling only your team can raise.
Ready to see how Alhena grounds every answer in your verified product data? Book a demo or start free with 25 conversations.

Frequently Asked Questions
Why does my AI agent give wrong answers even with a knowledge base?
Most inaccurate AI answers trace back to ambiguous or contradictory source content, not model failures. When two pages state different return windows or policies, the AI retrieves both and picks one. Fixing the source documentation is the fastest path to accuracy.
What format should my knowledge base be in for AI retrieval?
Markdown is ideal because it preserves semantic structure (headings, lists, tables) without visual noise. If your docs are in HTML, use semantic tags like h2 and table rather than styled divs. Alhena automatically converts HTML to Markdown during ingestion.
How do I structure headings for better AI retrieval?
Use one topic per heading, match customer language ("Returns After 30 Days" not "Extended Resolution Window"), maintain clean H1-H2-H3 hierarchy, and provide the answer in the first sentence under each heading.
What is chunking and why does it matter for my documentation?
RAG systems split documents into chunks of a few hundred tokens each and retrieve the most relevant ones at query time. If your content depends on surrounding context to make sense, individual chunks become meaningless when retrieved alone. Write each section to be self-contained.
How often should I audit my knowledge base for AI accuracy?
Run a quick audit monthly: check your top 10 support questions have clear single-section answers, remove duplicate facts, split compound headings, and review flagged low-confidence conversations from your AI agent.
Does Alhena AI require me to rewrite all my documentation?
No. Alhena handles HTML-to-Markdown conversion, semantic chunking, and navigation stripping automatically. What you should fix manually are contradictions between pages, ambiguous phrasing, and implicit context that no platform can resolve for you.