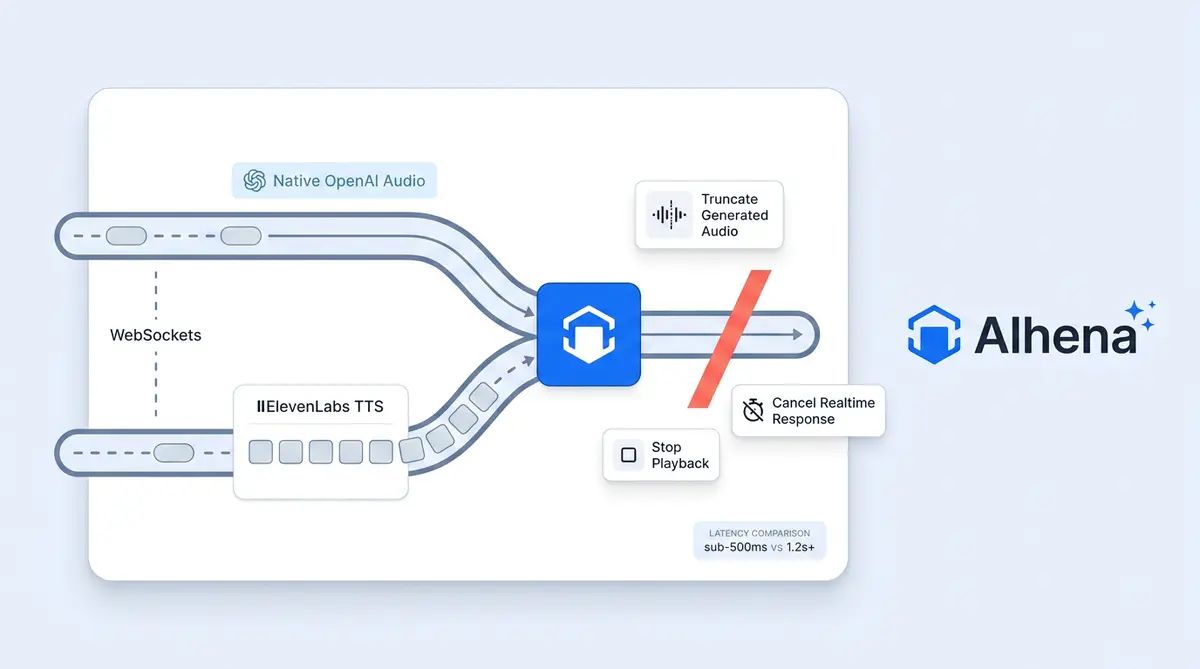
A caller dials an Alhena-powered phone number. The audio doesn't enter a traditional IVR tree. It enters a real-time, bidirectional media stream where every 20 ms of caller audio is analyzed, turned into intent, routed to tools and knowledge, generated back as text, synthesized into speech, and streamed back. All inside a WebSocket that stays open for the entire call.
The target for voice agents: sub-second perceived latency. The caller feels like they're talking to a person, not waiting for a bot to think. If you’re building voice AI, here’s how the stack actually works.
For the full observability architecture behind this, see how Alhena traces, logs, and debugs AI conversations.
For a look at how this applies to after-hours calls, see how callback ticket creation turn dead-end calls into Monday morning resolutions.
Three services across the engineering team cooperate to make this work:
- Voice AI Server (FastAPI) is the real-time brain. It owns the Twilio Media Stream and the OpenAI Realtime session.
- AI Server owns knowledge retrieval, tool definitions, and bot profile configuration.
- App Server owns tickets, messages, helpdesk apps and integrations, and callback creation.
Most voice agents batch audio or poll for responses. This post traces a single phone call through all three, from the moment it lands to the moment it hangs up.
The Call Lands
In voice AI applications, a PSTN or SIP call hits Twilio. Twilio POSTs to our /twilio-voice-webhook endpoint. The Voice AI Server validates the Twilio HMAC signature (so nobody can spoof requests into the infrastructure), looks up the bot_profile_key from the SipDomain, To number, or ApplicationSid, and returns TwiML with a <Connect><Stream> directive. That directive tells Twilio: open a WebSocket to wss://voice-ai-server/twilio-stream and start streaming the call's media there.
Custom <Parameter> tags on the stream pass along bot_profile_key, is_sip_call, original_caller_number, and a Freshcaller call ID if the call originated from a Freshcaller bot. These are how the WebSocket handler knows which company this call belongs to and who's calling.
Two WebSockets, One Conversation
The Voice AI Server now holds two long-lived WebSockets simultaneously:
- Twilio to Voice AI Server: carries the caller's audio as G.711 μ-law at 8kHz, the native PSTN format.
- Voice AI Server to OpenAI Realtime: carries that same audio forward and gets back text, audio, and function calls.
A TwilioSessionManager orchestrates both. It runs two async coroutines in parallel via asyncio.gather: client_to_openai(ws) forwards Twilio frames to OpenAI, while _openai_to_client(ws) forwards OpenAI events back to Twilio. Nothing is batched. Nothing is polled. Every frame moves as soon as it arrives.
Session bootstrap
Before the caller hears anything, the server fires a session.update on the OpenAI Realtime socket to configure the voice (per-brand voices and voice ID from voice_config), speech speed, the complete system prompt fetched from the AI server with company-specific context (no model training, machine learning fine-tuning, or data labelling needed) (source=PHONEuser metadata, and business hours), and the tool schema assembled by ToolHandlerFactory.get_all_tool_schemas.
Audio formats are set to g711_ulaw for both input and output so caller audio passes straight through without resampling. Turn detection uses server_vad with a threshold of 0.9, tuned high to avoid false barge-ins from background noise on phone lines. Noise reduction is set to near_field, optimized for a phone held close to the face.
The moment the session is up, the server fires the greeting. The caller hears a voice within a beat of picking up.
Audio In: Caller to AI
Every Twilio media frame (roughly 20ms of μ-law audio, base64-encoded) arrives and the server does one thing: update latest_media_ts and call append_audio_b64 to push the payload into OpenAI's input_audio_buffer. OpenAI's server-side VAD decides when the user has finished speaking and fires speech_started and committed events.
No local STT step sits in the critical path. The system leans on OpenAI's native audio understanding for the fastest possible loop.
For conversation logging, an external transcriber runs asynchronously. When configured (Cartesia "ink-whisper" or ElevenLabs Scribe), the server calls conversation.item.retrieve on OpenAI to pull back the raw user audio once the item is committed, then transcribes it in the background while the assistant is already responding. Transcription never blocks the conversation.
Audio Out: AI to Caller
Two modes, chosen per brand:
Native OpenAI audio. The Realtime speech-to-speech models generate audio tokens directly. response.audio.delta events arrive containing μ-law 8kHz audio. The server base64-wraps them and pushes them straight down the Twilio WebSocket as media events. Zero extra network hop. Lowest latency path.
External TTS via ElevenLabs. OpenAI generates text-only output. Text deltas stream into an ElevenLabs WebSocket, which returns μ-law 8kHz audio chunks (requested as ulaw_8000 for drop-in Twilio compatibility). ElevenLabs uses a chunk_length_schedule of [120, 160, 250, 290], telling it to begin generating as soon as about 120 characters are in. Speech production starts before the complete sentence is even written. Building on this approach is what maintains the sub-second feel even with an extra TTS provider in the loop.
Barge-In: The Make-or-Break Moment
The caller starts talking while the AI is mid-sentence. If the system doesn't handle this instantly, the illusion breaks. Research from AssemblyAI confirms delays beyond 300ms trigger perceptible unnaturalness in conversation.
When input_audio_buffer.speech_started fires, three things happen in the same tick:
- Local TTS cancelled:
_cancel_tts()kills any in-flight ElevenLabs synthesis. - OpenAI stopped:
openai_session.response.cancel()tells the models to stop generating. - Twilio buffer flushed: a
clearevent sent viasafe_send_jsonempties Twilio's jitter buffer so any audio already queued past the speaker's ear gets dropped.
Without that third step, the caller keeps hearing the AI for another half second after they've started talking. That half second is what separates "this feels like a person" from "this feels like a robot."
Tool Calls Mid-Conversation
When the model decides to call a tool, response.done arrives with a function_call item. The server schedules execution in the background so the reader coroutine doesn't block, then starts looping a short thinking sound (echo-pop.ulaw) every 3 seconds if the tool takes more than 500ms. The caller never hears dead air.
The tool roster for phone conversations:
- get_knowledge hits the AI Server's
/voiceagent/search_knowledge_base/RAG pipeline - transfer_to_human triggers
client.calls(call_sid).update(twiml=...)with a<Dial>verb, handing off mid-call with correct caller ID logic (outbound ID for SIP, original number for PSTN) - create_callback_ticket calls the App Server to schedule a human callback
- end_call gracefully closes the Twilio stream
- Dynamic tools fetched from the AI Server's
/voiceagent/get_available_tools/are forwarded to/voiceagent/execute_tool/for company-specific logic
Tool output returns to OpenAI as a function_call_output item, followed by response.create(). The model continues its turn with the result in context.
Enterprise Production Safety Nets
Inactivity watchdog. After 30 seconds of silence, the AI asks "Are you still there?" Another 30 seconds of silence ends the call gracefully.
Max duration. Hard cap of 30 minutes per call with a polite wrap-up before cutoff.
Credit verification. Before opening the OpenAI session, the server checks the bot profile for available credits. No credits, no session, no wasted compute.
Graceful Kubernetes draining. A DrainingState with signal handlers means enterprise rolling deployments never hang up a live call. The /health-check/ready probe returns 503 once draining starts, routing new connections elsewhere, but existing WebSockets finish naturally.
Request validation. Every webhook and WebSocket upgrade is validated against Twilio's HMAC signature.
Observability
Every call is traced end-to-end with Opik. The session trace wraps child spans for each tool invocation, TTS synthesis, STT transcription, and response.done event, including token usage for accurate cost attribution across OpenAI, ElevenLabs, and Cartesia. The opik_trace_id propagates back to the App Server so traces link directly to tickets in the dashboard. OpenTelemetry handles request-level tracing, and all messages sync back to the App Server so the complete transcript appears in the standard conversations UI alongside chat conversations.
Why It Feels Sub-Second
Seven engineering decisions compound to create the perception of instant response:
- No STT in the critical path. OpenAI Realtime handles user audio natively. No Whisper detour.
- Streaming per-chunk, not per-sentence. Audio in and out moves per frame. We never wait for full sentences before playing.
- Server-side VAD on OpenAI. Turn detection happens inside OpenAI's infrastructure, not round-tripped through ours.
- ElevenLabs chunk scheduling. TTS begins speaking before the LLM finishes writing.
- Background tool execution with thinking sounds. Tool calls never cause dead air.
- μ-law end-to-end. G.711 at 8kHz from Twilio through OpenAI and back. Zero resampling.
- Triple barge-in cancellation. Local TTS, model generation, and Twilio jitter buffer all cleared in one tick.
Industry benchmarks from Hamming AI put the median production voice agents at 1.4-1.7 seconds. This architecture targets sub-800ms for most interactions. The caller doesn't perceive speed. They perceive naturalness. The conversation just flows.
To see how this low-latency stack powers actual shopping interactions, read our breakdown of voice commerce UX patterns.
Want to hear what sub-second voice AI sounds like on your product catalog? Book a demo or start with 25 free conversations.

Frequently Asked Questions
How does Alhena Voice achieve sub-second response times over the phone?
Alhena Voice removes speech-to-text from the critical response path by using OpenAI's native audio understanding. Audio flows as G.711 μ-law from caller to AI and back without resampling, eliminating codec conversion latency. Combined with chunk-scheduled TTS and server-side VAD, most interactions complete in under 800ms.
What is the dual WebSocket architecture in real-time voice AI systems?
Alhena runs two simultaneous WebSocket connections per call: one carrying the caller's audio from Twilio (G.711 μ-law at 8kHz, 50 frames per second) and one connected to OpenAI's Realtime API for native speech understanding. The orchestrator sits between them, routing audio bidirectionally and coordinating state like barge-in events across both connections.
How does barge-in detection work without the AI talking over the caller?
When the caller speaks during AI playback, three cancellations fire simultaneously: Twilio's audio buffer is cleared with a WebSocket clear message, OpenAI receives a response.cancel event to stop generating, and local TTS state resets. The Twilio buffer flush is critical because without it, queued audio chunks continue playing for 60-80ms after interruption.
Why does Alhena Voice use G.711 μ-law instead of higher-quality codecs?
G.711 μ-law is the native codec of telephone network voices. Since OpenAI's Realtime API also accepts μ-law natively, the entire pipeline operates without a single resampling step. The creative engineering here: each codec conversion adds 5-15ms of latency and introduces interpolation artifacts. Keeping μ-law end-to-end saves 10-30ms in the critical path.
What happens during tool calls when the AI needs to look up order information mid-conversation?
A thinking sound loops every 3 seconds so the caller never hears dead air. The tool call (order lookup, inventory check, return processing) executes in the background via Alhena's Product Expert or Order Management Agent. When the result returns, the model continues with the data in context. OpenAI's async function calling allows the model to maintain conversational flow during execution.
How does Alhena Voice handle Kubernetes deployments without dropping live calls?
Rolling deployments use extended termination grace periods matching maximum call duration. When a pod receives SIGTERM, it stops accepting new WebSocket connections and deregisters from the load balancer. Existing calls continue to completion. New calls route to fresh pods. The result: multiple daily deployments with zero dropped calls.
What is the difference between silence-based and semantic Voice Activity Detection?
Silence-based VAD waits for a fixed duration of quiet (typically 600ms) before deciding the speaker finished. Semantic VAD uses the language model's understanding of conversational structure to detect turn boundaries earlier. For ecommerce calls where callers pause to read order numbers, semantic VAD avoids premature interruption while still responding 100-200ms faster than silence-only approaches.
How does ElevenLabs chunk scheduling reduce TTS latency in voice AI?
Instead of waiting for the full AI response before starting speech synthesis, ElevenLabs begins generating audio once approximately 120 characters accumulate. The first audio chunk reaches the caller while the model is still writing the rest of the sentence. This overlapping of generation and playback keeps perceived latency under one second even with an external TTS provider in the loop.
Can Alhena Voice transfer calls to human agents without disconnecting?
Yes. The orchestrator updates the active call's TwiML instruction using Twilio's call SID with a Dial verb. The transfer happens on the live call without hanging up or redialing. The caller hears a brief transition message and connects directly to the support queue. Call context from the AI conversation is passed to the human agent.
What latency do competing voice AI platforms typically achieve versus Alhena?
Industry benchmarks show the median production voice agents take 1.4-1.7 seconds to respond, with P90 latency reaching 3.3-3.8 seconds. Best-in-class platforms like Vapi claim ~465ms in optimal configurations. Alhena Voice targets sub-800ms for most interactions by eliminating STT from the hot path, streaming per-chunk, and maintaining zero-resampling G.711 architecture end-to-end.