The Problem with "Remembering"
Most AI systems don't remember anything. They process a conversation, respond, and forget. The next time a customer shows up, the AI starts from zero, with no ability to recall previous interactions or past customer interactions. Some AI platforms bolt on a chat history lookup, but that's retrieval, not memory. There's a difference between finding an old transcript and actually knowing that a customer's wife is named Sarah, that they prefer email over phone, and that they cancelled their Enterprise plan three months ago.
Alhena's Unified Memory was built to close that gap. We published the product story earlier this year, covering what memory does and why it matters. This post goes deeper. It covers the engineering: how facts get extracted from conversations, how memory evolves over time without losing history, and how privacy isolation works inside the database layer.
If you're an engineer evaluating AI memory systems, AI agents, and comparing memory architectures, or you're curious about the architecture behind AI powered ecommerce intelligence and agentic commerce, this is the post for you.
Two Layers, Not One: Memory + Profile
Unified Memory isn't a single data store. It's two complementary layers that serve different purposes at runtime.
UserMemory holds free-form facts, preferences, pain points, and shopping interests. It's a single evolving bullet-point string per user, fed directly into the LLM prompt for personalization. Think of entries like "prefers email over phone," "interested in red and black handbags," or "had a bad experience with shipping delays last quarter."
UserProfile holds structured identity information: name, email, phone, company, role, industry, address, timezone, plus a JSON relationships dictionary. Entries like "wife is named Sarah" or "dermatologist is Dr. Kim" live here. The profile powers deterministic lookups and relationship-aware responses without relying on the LLM to parse unstructured text.
Both layers are partitioned by (bot_profile, user_identifier), which means every company's customer data is hard-isolated at the database level. There's no shared memory pool across tenants. This two-layer design lets Alhena's AI Shopping Assistant combine structured identity in an agentic workflow to ("this is Jennifer, IT admin at Acme Corp") with rich contextual behavioral data and conversation context ("she's been comparing moisturizers for sensitive skin for two weeks") in every response.
Extraction: Turning Conversations into Structured Facts
Memory extraction doesn't happen in real time. It runs as an async batch job after a conversation ends. When a customer returns, a Celery task scans for their recently closed tickets that haven't been processed yet. Up to four tickets per cycle get sent to the AI server's extraction pipeline, which runs with a 10-minute soft timeout and 15-minute hard timeout.
A MemoryExtractionLog row is written for every attempt, including ones that produce zero facts. Nothing is ever re-extracted by accident.
Why batch, not real-time?
This is a deliberate trade-off. Real-time extraction would mean running an LLM call on every message, adding latency and cost to live conversations. Batch extraction after ticket close provides richer context, is cheaper to scale, safe to retry on failure, and produces higher-quality facts because the model sees the full conversation context rather than attempting summarization or compression of partial messages. Unlike systems that use summarization to compress context windows, not a fragment.
The 5W1H fact schema
Raw conversation snippets are messy. "Oh yeah, my wife Sarah mentioned Dr. Kim recommended that serum" contains multiple facts about multiple people. Alhena doesn't store raw snippets. Every extracted fact gets coerced into a structured Pydantic model:
- Who: "user," "user's wife," "user's company"
- What: "has Enterprise plan," "prefers email"
- When: "for 2 years," "since last month"
- Where: "in Austin"
- Why: "because not tech-savvy"
- How: "via email," "using Safari"
- Text: a standalone natural-language version of the fact
This schema is what makes attribution possible. When the model later encounters "Sarah prefers the gentle cleanser," it knows Sarah is the user's wife, not the user herself. That distinction matters for product recommendations and gift suggestions and personalized products.
Three models, three jobs
Each component of the extraction pipeline uses purpose-built models for each step:
- Fact extraction runs on GPT-5 mini (minimal reasoning mode), optimized for throughput on closed tickets
- Profile extraction runs on GPT-4.1 mini, which handles structured entity pulls like names, companies, and relationships
- Retrieval-time filtering uses Gemini 2.5 Flash Lite, only activated when a user has accumulated enough memory to need ranking
This multi-model approach keeps costs low while maintaining extraction quality. A single large model would be overkill for routine fact extraction and too slow for real-time retrieval filtering.
ADD, UPDATE, DELETE: Memory Management That Stays Current
The extraction prompt doesn't blindly append new facts. It receives the existing memory string plus known relationships, then returns one of three operations per fact:
- ADD: net-new information and context the system hasn't seen before
- UPDATE: a refinement, correction, or state change that supersedes an existing fact
- DELETE: a previous fact was factually wrong (this is rare)
Two special-case rules are worth calling out.
Shopping interests are additive by default. "Interested in red" plus "interested in black" becomes "interested in red and black." Interests only get removed on explicit rejection ("I don't want red anymore"). A customer looking at black boots today hasn't stopped liking the red ones they browsed last week.
Cancellations are updates, not deletes. "Cancelled subscription" supersedes "has Enterprise plan" rather than erasing it. The history isn't lost. This is important for support concierge scenarios where an agent needs to know a customer had Enterprise previously, even if they've since downgraded.
Evolution Chains: Version Control for Customer Knowledge
Only one memory record is active per user at any time. When a new extraction changes the memory text, the system follows a precise sequence:
- Compute the MD5 hash of the new memory text
- If the hash matches the current record, just update source tracking (no new row, no wasted storage)
- If the hash differs, flip the old row to
is_active=False, insert a new row with anevolved_frompointer to the old one, and merge source tracking metadata across versions inside an atomic database transaction
The result is a full lineage chain. You can walk backwards through every version of a user's memory and see exactly which ticket and which message introduced each change. Think of it as Git for customer facts.
This design serves two purposes. First, it's an auditability backbone. Combined with MemoryExtractionLog and per-row source tracking (channel, ticket ID, message IDs), you can always answer the question: "Where did this fact come from?" That's a strong story for compliance teams evaluating AI systems under GDPR or CCPA requirements.
Second, it enables debugging. When a customer says "the AI told me something weird," support engineers can trace the issue back through the memory lineage to find which conversation introduced the problematic fact, then correct it.
Evolution, Not Expiration: The Honest Decay Story
Here's the part worth being direct about. Alhena's memory does not auto-decay today. There's no TTL field, no confidence score that degrades over time, no temporal decay function, no background job that prunes old content. Memories are persistent. They remain until they're updated through the evolution chain or soft-deleted through an explicit API call.
This is a deliberate design choice, not a gap.
Time alone isn't a signal that a fact is wrong. A customer's skin type doesn't expire after 90 days. Their shipping address doesn't become less accurate just because six months passed. In ecommerce applications and support contexts, the trigger for memory change is new information, not elapsed time. When new information arrives, like a customer mentioning they moved to a new city, the evolution chain handles it. A TTL would have silently erased their old address without knowing if it was still correct.
Returning customers benefit from long memory. McKinsey reports that companies generate 40% more revenue from personalization than average players. That lift depends on the AI actually knowing who it's talking to, even across long gaps between interactions.
Soft-delete is the persistent retention control. Nothing is physically removed from the database. Deletions flip an is_deleted flag, preserving the audit trail. Companies can also disable memory extraction entirely at the tenant level with a single toggle (is_memory_extraction_enabled), which stops all future extraction without touching existing persistent data.
What triggers memory evolution? Three things: re-extraction on the next closed ticket (automatic), explicit corrections from the customer during conversation, or admin action through the API.
Retrieval: Getting the Right Memory to the LLM
Storing memory is only half the problem. The other half is getting the right memory into the prompt at the right time, without blowing up the LLM context window or adding latency.
When a chat turn starts, the ChatOrchestrator loads memory through a MemoryFetcher with a simple branching rule:
- 20 memory lines or fewer? Return everything. It's cheap, and more context rarely hurts at this scale.
- More than 20 lines? Run an LLM filter (Gemini 2.5 Flash Lite) that picks the most relevant lines for the current query. If the LLM filter fails, fall back to the most recently updated lines.
There are no vector embeddings in this pipeline. That's a deliberate choice. Memory entries are dense and short (bullet points, not document chunks). LLM-selected relevance outperforms cosine similarity on this shape of data, and it keeps the infrastructure lean. No embedding model to maintain, no vector database to tune, no re-indexing pipeline.
Memory and profile are injected into the agent prompt through separate templates. The UserProfile provides structured identity info (name, company, relationships) as a formatted block. The UserMemory provides behavioral context as bullet points, wrapped in guidelines that tell agents to personalize proactively, reference memory naturally, and let the current conversation override memory when they conflict. The agent also knows not to re-recommend items the customer already purchased.
This separation means the agent architecture can treat identity and behavior as distinct inputs, weighting them differently depending on the task. An order status lookup leans on profile. A product recommendation leans on memory.
Episodic, Semantic, and Working Memory: Where Alhena Fits
AI memory architecture research identifies several distinct types of memory that agentic AI systems use. Understanding these different memory types helps explain the design choices behind Alhena's approach to persistent customer knowledge.
Episodic memory stores specific interactions and events. In an ecommerce context, this is the record of what happened during a particular conversational interaction: the customer asked about a serum, the AI recommended three options, and the customer purchased one. Alhena's MemoryExtractionLog captures episodic memory records for every extraction attempt, building a complete episodic memory timeline, preserving a persistent timeline of what was discussed and when.
Semantic memory stores generalized facts and knowledge extracted from episodes. "Customer prefers fragrance-free products" is semantic memory distilled from multiple conversations. Alhena's UserMemory layer is fundamentally a semantic memory store, one of the richest semantic memory implementations in ecommerce AI. The 5W1H extraction process transforms raw episodic conversation data into structured semantic facts that persist across sessions.
Working memory is the short term memory used during an active conversation. It holds the immediate context: what the customer just said, what the AI just recommended, and the current state of the dialogue. In Alhena's architecture, working memory lives in the ChatOrchestrator's active session. It's ephemeral by design. Once the conversation closes, the valuable parts are extracted into long term memory through the batch pipeline.
Most AI systems for ecommerce only implement working memory. They hold context within a session but lose everything when the session ends. Some platforms add basic episodic retrieval by searching past chat logs. Alhena is one of the few systems that implements all three types of memory with a clear separation between them. The UserProfile provides structured long term memory for identity. The UserMemory provides semantic long term memory for preferences and behavior. And the active conversation provides context memory (working memory) for immediate reasoning.
Why No Vector Database or Embeddings?
If you've worked with large language models, you might expect a memory system to use vector embeddings and a vector database for retrieval. Retrieval augmented generation (RAG) is the standard pattern: embed documents into a vector space, then use vector search to find relevant chunks when the LLM needs context. Most AI search and knowledge base systems rely on this approach.
Alhena's memory system doesn't use vector embeddings or a vector database. This is a deliberate architectural choice, not a limitation.
The reason comes down to data shape. Vector search excels at finding semantically similar content across large, heterogeneous document collections. Product catalogs, help center articles, and knowledge bases are perfect vector search candidates. Each document is long enough that embedding captures meaningful semantic structure, and the collection is large enough that brute-force search is impractical.
Customer memory is different. Each user's memory is a short list of bullet-point facts, rarely exceeding 20-30 lines. At this scale, an LLM can evaluate every line directly. There's no need for an approximate nearest-neighbor search when you can check every candidate. The LLM-based filter running on Gemini 2.5 Flash Lite outperforms cosine similarity because it understands contextual relevance, not just semantic proximity. "Prefers email" and "had a bad experience with phone support" are semantically distant in embedding space but contextually related when a customer asks about contact options.
Skipping the vector layer also reduces compute costs, improves scalability, and lowers operational overhead. No embedding model to run on every memory update. No vector index to maintain and re-index. No vector database infrastructure to scale. The memory system stores plain text in a relational database, retrieves it with standard queries. Retrieved facts are retrieved by user identifier and retrieved facts feed directly into the prompt, and uses a lightweight LLM call only when the memory list exceeds 20 items. For the typical ecommerce customer with 5-15 memory lines, retrieval is a simple database read with zero LLM token overhead.
To be clear, Alhena's broader platform does use vector search and embeddings for the product catalog and knowledge base retrieval pipelines use vector search and RAG for product discovery, where embeddings are the right tool. Customer memory just isn't the right shape for vector search.
Agentic Memory in Practice
Unified Memory sits at the foundation of Alhena's agentic AI architecture. Two specialized agentic agents use memory differently. The Product Expert Agent draws on semantic memory to make contextual product recommendations. If the memory says a customer has sensitive skin, the agent filters recommendations accordingly without the customer needing to repeat that preference in every conversational session.
The Order Management Agent uses profile data for operational tasks: checking order status, processing returns, updating shipping addresses. It pulls structured identity information from the UserProfile to perform these actions without asking the customer to re-verify details they've already shared.
Both agents share the same memory store. When the Product Expert Agent learns that a customer is shopping for their daughter's birthday, the Order Management Agent can later infer that a recent purchase might be a gift and adjust its return instructions accordingly. This cross-agent memory sharing is what makes agentic commerce and agentic AI systems feel coherent rather than fragmented. The customer talks to one brand, not a collection of disconnected bots.
Memory also powers proactive engagement. When a customer who previously bought a winter moisturizer returns in spring, the AI shopping assistant can proactively suggest a lighter formula. This kind of seasonal, personalized outreach isn't possible with short term session memory alone. It requires persistent, semantically rich long term memory that spans months of customer interactions.
Agentic Memory vs. Conversational Memory: What Makes the Difference
The AI industry uses the terms "agentic memory" and "conversational memory" in overlapping ways, but they refer to different memory types with different engineering requirements. Understanding the distinction helps explain why Alhena's agentic approach produces better results than conversational-only systems.
Conversational memory keeps track of what was said within a single dialogue. Most LLM chatbots do this by appending each message to the LLM's context window. The conversation feels coherent because the LLM can see everything that was said, but once the session ends, the conversational memory is gone. Some systems extend conversational memory across sessions by loading past transcripts, but this approach scales poorly. A customer with 50 past conversations would need thousands of LLM tokens just to reload their history, making every response slower and more expensive.
Agentic memory goes beyond conversational context. Agentic AI systems need to remember facts, make decisions, and take actions across different tools and channels. An agentic shopping assistant that remembers a customer's skin type, gift preferences, and past purchases can proactively recommend products, populate carts, and adjust its conversational tone based on the customer's communication style. This requires different memory types working together: episodic memory for interaction history, semantic memory for extracted facts, and procedural memory for learned preferences about how the customer likes to be served.
Alhena's Unified Memory was designed for the agentic use case from the start. The 5W1H extraction schema converts conversational data into persistent semantic facts. The evolution chain keeps those facts current without losing history. The two-layer model (UserMemory + UserProfile) separates behavioral memory from identity memory so each agentic component can access what it needs. And the LLM-ranked retrieval ensures that only the most relevant memory reaches the prompt, keeping LLM token usage predictable even for customers with extensive interaction histories.
This is why Alhena's memory architecture differs from general-purpose LLM memory frameworks. Tools like MemGPT or Mem0 solve the general problem of giving any LLM persistent context. They're designed for broad agentic use cases and flexible memory types. Alhena solves a narrower, deeper problem: building persistent, structured ecommerce memory: giving ecommerce AI agents the specific memory types they need (product preferences, relationship data, purchase history context, communication preferences) in a format that's structured enough for agentic actions and auditable enough for enterprise compliance.
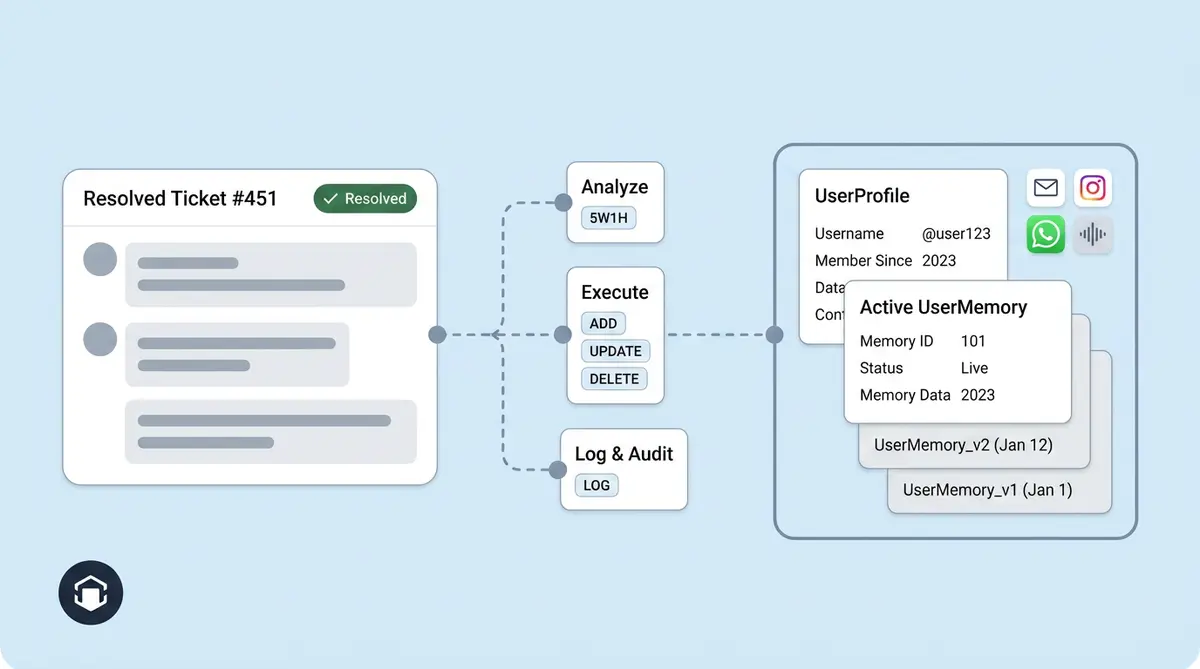
The Data Flow: From Ticket Close to Agent Prompt
Here's the end-to-end data flow, from a conversation ending to memory appearing in the next conversation's LLM prompt. Each step in the pipeline is designed for reliability and scalability.
Step 1: Trigger
A customer's conversation closes (ticket resolved, chat ended, email thread completed). The app server's Celery task check_and_trigger_memory_extraction picks up the closed ticket. It checks the MemoryExtractionLog to confirm this ticket hasn't been processed before, then sends it to the AI server via POST /memory/add/. Up to four tickets are batched per cycle to control compute spend.
Step 2: Fact Extraction
The AI server's Celery worker runs extract_and_store_memory_task with a 10-minute soft timeout and 15-minute hard timeout. The fact extraction model (GPT-5 mini) receives the full conversational transcript plus the customer's existing memory and relationships. It returns a list of 5W1H-structured facts, each tagged with an operation: ADD, UPDATE, or DELETE. The profile extraction model (GPT-4.1 mini) runs in parallel, pulling structured entity data like names, companies, roles, and relationship mappings.
Step 3: Storage and Evolution
The MemoryStorageService takes the extracted facts and applies them. For ADD operations, new facts are appended to the memory string. For UPDATE operations, existing facts are replaced with their updated versions. The service then computes an MD5 hash of the final memory text. If the hash matches the active record, only source tracking metadata is updated. If the hash differs, the old record is deactivated and a new record is inserted with the evolved_from pointer, creating the next link in the evolution chain. All of this happens inside an atomic database transaction.
Step 4: Retrieval at Conversation Start
When the same customer starts a new conversation, the ChatOrchestrator calls the MemoryFetcher. The fetcher queries for the active memory record by (bot_profile, user_identifier). If the memory has 20 or fewer lines, all of it is returned directly. If it exceeds 20 lines, the retrieval filter (Gemini 2.5 Flash Lite) ranks lines by relevance to the current query. The retrieved memory entries and retrieved profile data are injected into the agent's system prompt via MEMORY_CALLING_CAPABILITY_TEMPLATE. The agent now has full context about who it's talking to without any additional token overhead from loading raw conversation logs.
The entire pipeline runs asynchronously. Customers never wait for extraction to complete. The AI agents serve conversations with whatever memory was available at the start of the session. New memory from the current conversation will be extracted after it closes and available for the next interaction.
Privacy and Isolation by Design
Every model in the memory system (UserMemory, UserProfile, MemoryExtractionLog) carries a bot_profile foreign key. All queries and API endpoints are scoped by this key, so one company's memory is invisible to every other company. This isn't application-level filtering that could be bypassed with a bad query. It's structural isolation at the data layer.
Identity resolution across channels
Customers interact across web chat, email, Instagram DMs, WhatsApp, and voice. Alhena resolves user identity through a strict priority chain: user_id > email > external_user_id > customer_id. This lets a person's memory follow them across channels without fragmenting into separate profiles for each touchpoint.
When two user identifiers turn out to be the same person (common when someone starts on web chat and later contacts support via email), a memory migration endpoint merges their records. The result is a single, unified memory for each real person, regardless of how many channels they've used.
What's stored and what's controlled
Memory text is stored as extracted. The system relies on the extraction prompt's rules (only user-stated facts, no assumptions, no inferences from browsing behavior) rather than downstream PII scrubbing. This is an intentional design boundary: the extraction agents capture what customers tell you, not what you observe about them.
Companies have three levels of control:
- Tenant-level kill switch: disable all memory extraction with a single flag
- API-driven soft delete: remove specific memories while preserving the audit trail
- Full auditability: evolution chains plus source tracking mean every fact can be traced to its origin conversation, down to channel, ticket, and individual messages
For brands operating under GDPR or regional data requirements, that traceability is the compliance backbone. You can always answer "where did this fact come from?" and "when was it last updated?" for any piece of customer memory.
Why This Architecture Matters for Ecommerce
The ecommerce AI market is projected to exceed $64 billion by 2034, according to Ringly's market analysis. As large language models become commodity infrastructure, the competitive advantage for agentic ecommerce platforms shifts to what you feed them. Two AI agents running the same base model will produce very different results when one has rich, structured customer memory and the other starts cold every conversation.
Memory architecture choices have direct revenue consequences. Barilliance research shows that sessions engaging with personalized product recommendations see up to a 369% increase in average order value. But personalization accuracy depends entirely on what the AI knows about the customer, and how accurately it knows it.
Alhena's approach (structured fact extraction via 5W1H, evolution chains instead of TTLs, multi-model pipelines, and no-vector retrieval) was designed for the specific shape of ecommerce customer data: short, dense, relationship-rich, and long-lived. Ecommerce brands have seen significant lifts in both conversion and average order value with Alhena's AI, and Unified Memory is a core part of what makes those numbers possible.
The self-improving architecture means memory gets better with every conversation. It doesn't decay, it doesn't fragment across channels, and it doesn't require your engineering team to maintain vector databases or embedding pipelines.
Ready to see how Unified Memory works for your store? Book a demo with Alhena AI or start for free with 25 conversations.

Frequently Asked Questions
How does Alhena extract customer memory from conversations?
Alhena runs async batch extraction after each conversation closes, not during the live chat. A Celery task sends up to four closed tickets to the AI server, where GPT-5 mini extracts facts into a structured 5W1H schema (who, what, when, where, why, how). Every extraction attempt is logged so nothing gets processed twice.
What is the 5W1H fact schema in Alhena's memory system?
Every extracted fact is structured into six fields: Who (the subject, like "user" or "user's wife"), What (the fact itself), When (timeframe), Where (location), Why (reason), and How (method). This structured format lets the AI distinguish between facts about the customer and facts about people in the customer's life, which is critical for accurate personalization and gift recommendations.
Does Alhena's memory expire or decay over time?
No. Alhena uses evolution instead of expiration. There's no TTL, no confidence decay, and no background pruning job. Memories are persistent. They remain until new information supersedes them through the evolution chain, or until an admin soft-deletes them via the API. This design reflects the reality that time alone doesn't make a fact wrong.
How does Alhena keep customer memory isolated between companies?
Every memory record carries a bot_profile foreign key, and all database queries are scoped by this key. This provides structural tenant isolation at the data layer, not just application-level filtering. One company can never access another company's customer memory. Companies can also disable memory extraction entirely with a single toggle.
What are evolution chains in Alhena's memory architecture?
Evolution chains are version control for customer knowledge. When memory text changes, the old record is deactivated and a new record is inserted with an evolved_from pointer to the previous version. This creates a full lineage you can walk backward through, tracing every change to its source conversation, ticket, and message ID.
Does Alhena use vector embeddings for memory retrieval?
No. Alhena uses LLM-ranked retrieval instead of vector search. For users with 20 or fewer memory lines, everything is returned. For larger memory sets, Gemini 2.5 Flash Lite selects the most relevant lines for the current query. This approach outperforms cosine similarity on short, dense bullet-point memory and eliminates the need for embedding models or vector database infrastructure.
How does Alhena handle customer identity across channels?
Alhena resolves identity through a strict priority chain: user_id, then email, then external_user_id, then customer_id. When two identifiers turn out to be the same person, a memory migration endpoint merges their records into a single unified profile. This means memory follows customers across web chat, email, Instagram DMs, WhatsApp, and voice without fragmenting.
What models power Alhena's memory extraction pipeline?
Three models handle different parts of the pipeline. GPT-5 mini (minimal reasoning) handles fact extraction for throughput. GPT-4.1 mini handles profile extraction for structured entity pulls like names and relationships. Gemini 2.5 Flash Lite handles retrieval-time filtering when memory exceeds 20 lines. This multi-model approach balances cost, speed, and accuracy.