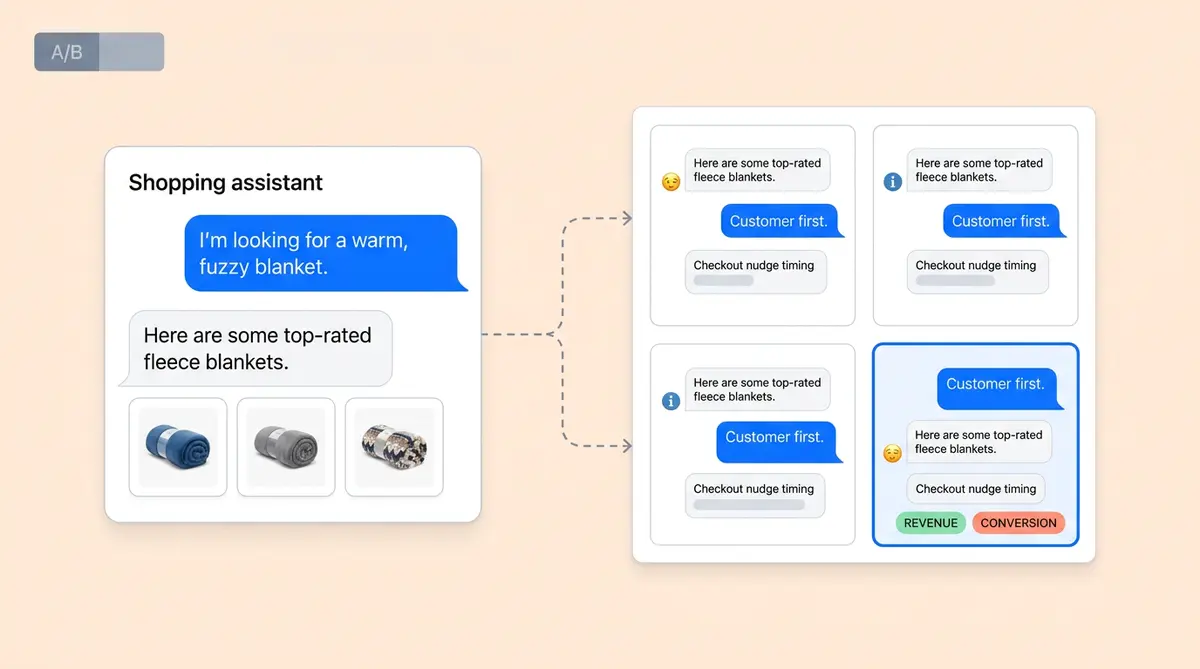
You've run your first round of A/B tests on your AI-powered shopping assistant, a tool that guides shoppers toward the right products. Greeting A beats Greeting B. Professional tone edges out casual. Early checkout nudges convert better than late ones. Each test took two weeks and yielded one answer. At that pace, testing five variables across two levels each means ten sequential tests and five months of calendar time before you've covered the basics.
Multivariate testing (MVT) collapses that timeline. Instead of changing one variable per experiment, you test multiple variables simultaneously and measure how they interact. Our pillar guide on AI A/B testing for ecommerce flags multi-variable testing as a common mistake when teams aren't ready for it. This post is for teams that are.
When A/B Testing Hits a Ceiling
A/B tests assume variables are independent. Change the greeting, measure the result, optimize, and move on. But AI shopping assistants are systems where personalization variables interact. A casual greeting sets a customer journey expectation that a hard upsell three messages later violates. A formal tone paired with playful product information and descriptions creates dissonance that kills trust.
These these conversational interaction effects are invisible to sequential A/B optimization tests. You'd optimize the greeting in isolation, lock it in, then optimize the tone separately, never discovering that the combination of casual greeting + formal tone + delayed nudge outperforms every individual winner by 20%. According to PM Toolkit's experimentation research, interaction effects between variables can unlock 40 to 60% more value than testing each variable alone.
If your AI shopping assistant touches five or more configurable personalization variables in your AI-powered shopping experience and your team has already run foundational A/B tests on each one, you're ready for experimenting with MVT.
Full Factorial Design for AI Chat Variables
Factorial design is the engine behind MVT. You define your factors (the variables you want to test), assign levels (the variations for each factor), and create a test matrix that covers specific factor-level combinations.
Here's a concrete example. Say you want to test three chatbot variables:
- Greeting style (3 levels): proactive, highly personalized greeting, proactive generic, reactive
- Response tone (2 levels): conversational, professional
- Recommendation strategy (2 levels): collaborative filtering, content-based
A complete factorial design produces 3 x 2 x 2 = 12 unique variant cells. Every shopper who triggers the chatbot gets randomly assigned to one of 12 experiences. You measure the same KPIs and conversion metrics across all cells: core ecommerce KPIs: add-to-cart rate, product discovery metrics, checkout completion, AOV, and revenue per shopper conversation across products.
The power of this approach is that you get answers for all three factors in a single experiment, plus you learn and discover which specific combinations are optimized for the best results, not just which individual levels win on average.
Interaction Effects: The Real Payoff of MVT
Main results tell you the average performance of each level across all other variables. Greeting A converts 12% better than Greeting C on average. That's useful, but it's what an A/B test would have told you anyway.
Interaction effects are why you ran MVT. They tell you whether the difference between Greeting A and Greeting C changes depending on which tone or recommendation strategy or personalized approach is paired with it. If Greeting A + conversational tone converts 25% better than expected from their individual main effects, that synergy is real, measurable, and lets you refine and optimize, what no A/B test could detect.
For ecommerce chatbot optimization, the most common high-value interactions are:
- Greeting x Nudge timing: proactive greetings set urgency expectations that interact with when you present the checkout CTA
- Tone x Recommendation style: a casual tone with data-driven "customers also bought" recommendations can feel authentic, while the same tone with editorial picks can feel random, hurting product discovery
- Recommendation strategy x CTA copy: aggressive conversion language ("Add to cart now") paired with subtle product discovery creates friction that softer CTAs avoid
The Traffic Reality Check
Full factorial MVT has a hard constraint: sample size. To optimize each cell in your test matrix, you need enough conversations to detect meaningful differences in conversion rate. The standard formula: if your baseline conversion rate model assumes 5% and you want to detect a 20% relative lift with 80% power at 95% confidence, you need roughly 3,800 conversations per cell.
For our 12-cell example, that's 45,600 total chatbot conversations. If your ecommerce site generates 500 shopper chat sessions per day, this experiment runs for 91 days. Manageable for high-traffic ecommerce retailers. Impossible for most mid-market retailers without scale.
This is where teams either give up on MVT or make the smarter move: fractional factorial designs.
Fractional Factorial and Taguchi Designs: Testing More With Less
A fractional factorial design tests a carefully selected subset of the full factorial matrix. Instead of all 12 cells, you might run 6 or 8, chosen so that main effects remain estimable while some higher-order interactions are confounded (blended together and not individually measurable).
Taguchi orthogonal arrays formalize this approach. Enterprise testing platforms like SiteSpect support these designs natively. An L8 array, for example, lets you test up to seven two-level factors in just 8 runs, compared to the 128 runs a full factorial would require. You sacrifice the ability to measure every pairwise interaction, but you gain coverage of more factors within your traffic budget.
For AI shopping assistant optimization, the practical tradeoff works like this:
- Full factorial (12 cells): test 3 factors, measure all main effects and all interactions. Needs 45K+ conversations.
- Fractional factorial (6 cells): test the same 3 factors, measure all main effects and one pre-selected interaction. Needs 23K conversations.
- Taguchi L8 (8 cells): test up to 5 factors at 2 levels each, measure all main effects. Needs 30K conversations but covers more variables.
The rule of thumb: if you have fewer than 300 chat sessions per day, start with a Taguchi L4 or L8 array that covers your highest-priority optimization factors. If you have 500+ sessions per day, complete factorial on 2 to 3 factors is realistic. The MVT sample size calculator at Martech Zone helps you model this for your specific scale of traffic and baseline conversion rate.
Which Variables to Bundle, Which to Isolate: Strategies
Not every chatbot variable belongs in a multivariate test. Bundle variables into MVT when you have a strong hypothesis that they interact. Isolate variables that are likely independent.
Bundle together (likely interactions):
- Greeting style + checkout nudge timing (early conversation framing affects late-conversation conversion tolerance)
- Response tone + recommendation strategy (tone sets the register for how products and suggestions land)
- CTA copy + upsell aggressiveness (the language and the intensity need to match)
Test in isolation (likely independent):
- Avatar/brand icon design (visual, doesn't interact with conversational variables)
- Typing indicator speed (UX detail, unlikely to interact with content variables)
- Fallback escalation path (only triggered on failure, separate from the happy-path variables above)
When in doubt, run the MVT. If the interaction turns out to be zero, you've confirmed independence and can run faster A/B tests on those variables going forward. That's a useful finding, not a wasted experiment.
Reading MVT Results Without False Positives
A 12-cell MVT produces dozens of pairwise comparisons. If you evaluate each at 95% confidence, you'll find "significant" results by chance alone. This is the multiple comparisons problem, and it catches teams experimenting with multivariate experimentation off guard.
Three corrections to apply:
- Bonferroni correction: divide your significance threshold (0.05) by the number of comparisons. Simple, conservative, and appropriate for small MVTs with under 20 comparisons (SiteSpect applies this automatically).
- False Discovery Rate (Benjamini-Hochberg): less conservative than Bonferroni. Controls the proportion of false positives among all declared significant results. Better for larger experiments.
- Pre-registration: define your primary comparisons before the experiment starts. You're allowed one or two primary hypotheses tested at nominal alpha. Everything else is exploratory.
Focus your analysis on main effects first (which level of each factor wins on average), then check the pre-specified interaction hypotheses. Only after those are settled should you explore unexpected patterns, and label those as directional insights and signals that need confirmation.
How Alhena Helps You Optimize MVT Through Statsig
Running multivariate tests on an AI shopping assistant requires infrastructure that most ecommerce teams don't want to build from scratch. Alhena's AI-powered experimentation functionality, built on Statsig, handles the mechanics via its API: random assignment and segmentation of chat sessions into variant cells, real-time conversion tracking to optimize across all cells, and statistical analysis with automatic multiple-comparison corrections.
Because Alhena's Product Expert Agent is grounded in verified product information from trusted data sources with zero hallucinations, the variables you're optimizing (greeting, tone, recommendation logic) are the only things changing between cells. You don't have a confound from the AI making up different claims about products in different sessions.
Alhena's revenue attribution analytics track add-to-cart, cart value, checkout, AOV, and revenue per conversation at the session level, exactly the KPIs you need for each MVT cell. Brands like Tatcha (3x conversion, 38% AOV uplift) and Victoria Beckham (20% AOV increase) built their baselines on Alhena before running advanced experiments that pushed results even higher.
For teams using the holdout test methodology to measure incremental AI revenue, MVT becomes the next layer: once you've proven the AI drives incremental value, MVT helps you optimize the configuration that drives the most.
Getting Started: Optimize Your First MVT in Three Steps
- Pick two factors you suspect interact, then refine from there. Greeting style and checkout nudge timing are a strong first pair for most brands. Design a 2x2 matrix (4 cells). This is the smallest real MVT (SiteSpect calls this a basic factorial) and needs roughly 15,000 conversations.
- Pre-register your hypothesis. Write down which interaction you expect ("proactive greeting + early nudge will outperform the sum of their individual effects") before launching. This protects you from data-dredging after the fact.
- Run for the planned duration. Don't peek and stop early when one cell looks like it's winning. Sample sizes are calculated for a reason. If your traffic is borderline, switch to a fractional design rather than cutting the test short.
Ready to run multivariate experiments on your AI shopping assistant? Book a demo with Alhena AI to see the experimentation module in action, or start free with 25 conversations to build your baseline first.

Frequently Asked Questions
What is multivariate testing for AI shopping assistants?
Multivariate testing (MVT) changes multiple chatbot variables at once, such as greeting style, response tone, and recommendation strategy, and measures how they interact. Unlike A/B testing, which isolates one variable at a time, MVT reveals which specific combinations of settings drive the best conversion rates and revenue.
How does MVT differ from A/B testing for ecommerce chatbots?
A/B testing changes one variable per experiment and assumes variables are independent. MVT tests multiple variables simultaneously using factorial design, letting you detect interaction effects where certain combinations outperform what you'd predict from individual winners. Research from experimentation teams shows these interactions can unlock 40 to 60% more value. Enterprise platforms like SiteSpect, Optimizely, and Alhena support both A/B and MVT designs.
How many chat sessions do I need for a multivariate test?
Each cell in your test matrix needs roughly 3,800 conversations to detect a 20% relative lift at 95% confidence. A 2x2 design (4 cells) needs about 15,000 total conversations. A 3x2x2 complete factorial (12 cells) needs around 45,000. If your traffic is lower, fractional factorial or Taguchi orthogonal array designs (supported by platforms like SiteSpect) can cut the required sessions by half.
What is a Taguchi orthogonal array and when should I use one?
A Taguchi orthogonal array is a fractional factorial design that tests a balanced subset of variable combinations. An L8 array tests up to seven two-level factors in just 8 runs instead of the 128 a full factorial would need. Use it when your chatbot traffic is too low for full factorial but you want to optimize and screen five or more variables for main effects.
Which AI chatbot variables should I test together in MVT?
Bundle variables that likely interact: greeting style with checkout nudge timing, response tone with recommendation strategy, and CTA copy with upsell intensity. Isolate variables that are probably independent, like avatar design or typing indicator speed. If you're unsure whether two variables interact, include them in the MVT. A null interaction result is still valuable.
How do I avoid false positives in multivariate test results?
Apply a multiple comparisons correction. Bonferroni correction (used by platforms like SiteSpect, Optimizely, and similar MVT platforms) divides your significance threshold by the number of comparisons and works well for small MVTs. Benjamini-Hochberg (False Discovery Rate) is less conservative for larger experiments. Most importantly, pre-register your primary hypotheses before launching so you're not data-dredging after the fact.
Does Alhena AI support multivariate testing?
Yes. Unlike web-page MVT tools like SiteSpect that test visual elements, Alhena's experimentation module, built on Statsig, handles conversational AI-specific random session assignment to variant cells, real-time conversion tracking, and statistical analysis with automatic multiple-comparison corrections. Because Alhena's AI is grounded in verified product data, the only variables changing between cells are the ones you're testing.