Gartner predicts that 40% of enterprise applications will include task-specific AI agents by 2026. That's up from under 5% in 2025. The shift isn't theoretical anymore: companies are moving from monolithic AI pipelines to automation-first, specialized, multi-agent systems that plan, execute, and verify every interaction.
At Alhena AI, we lived this transition firsthand. Our RAG pipelines were best in class for answering product questions and handling customer queries. But as we onboarded more e-commerce brands with increasingly complex operations and needs, we hit the ceiling of what a single retrieval pipeline could do. So we tore it down and rebuilt our AI around a multi-agent architecture with planning at its core.
In this post, I'm sharing the technical details of what we built, why standard RAG wasn't enough, and how our Plan-Execute-Verify system works in production.
Where Standard RAG Falls Short
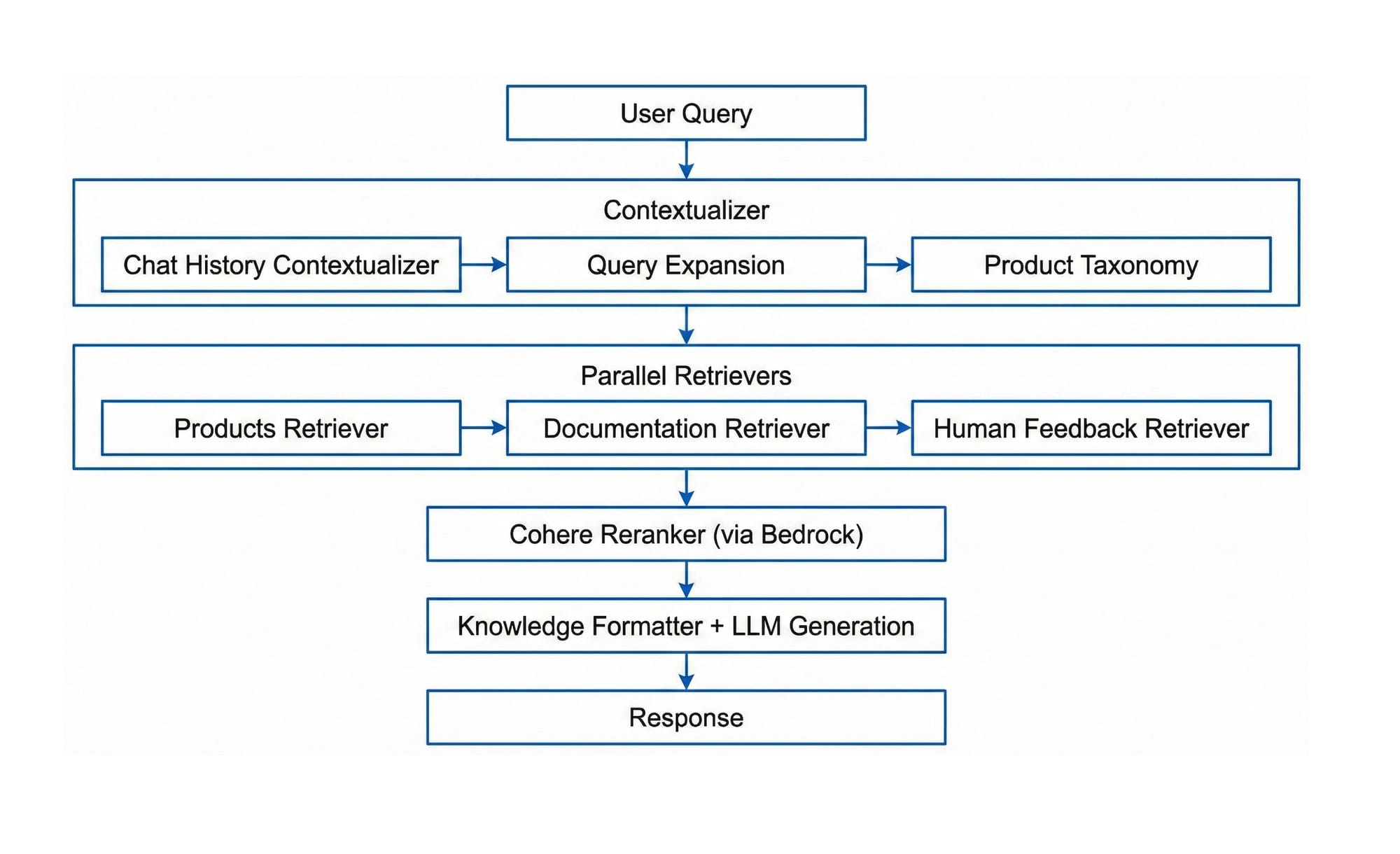
RAG (Retrieval-Augmented Generation) works well for straightforward question-answering. Retrieve relevant documents, pass them to the LLM, generate a response. But in production e-commerce use cases, three problems kept surfacing.
Context window bloat. As we added guardrails, safety rules, brand voice instructions, and tone guidelines, the system prompt ballooned. Even with today's larger context windows, stuffing more tokens in adds latency, increases cost, and causes hallucinations. The model loses attention to detail when it's drowning in instructions.
One pipeline for everything. A customer asking "where's my order?" went through the same knowledge retrieval as someone looking for "a red dress under $100 for a summer wedding." The order query doesn't need product catalog search. The product query doesn't need order APIs. But both got the same pipeline, wasting retrieval calls and returning irrelevant context.
No ability to adapt. A standard RAG pipeline is a straight line: retrieve, generate, done. There's no way to course-correct mid-execution, chain multiple actions, or recover gracefully when something goes wrong.
The Fix: Agent Architecture in AI with Plan-Execute-Verify
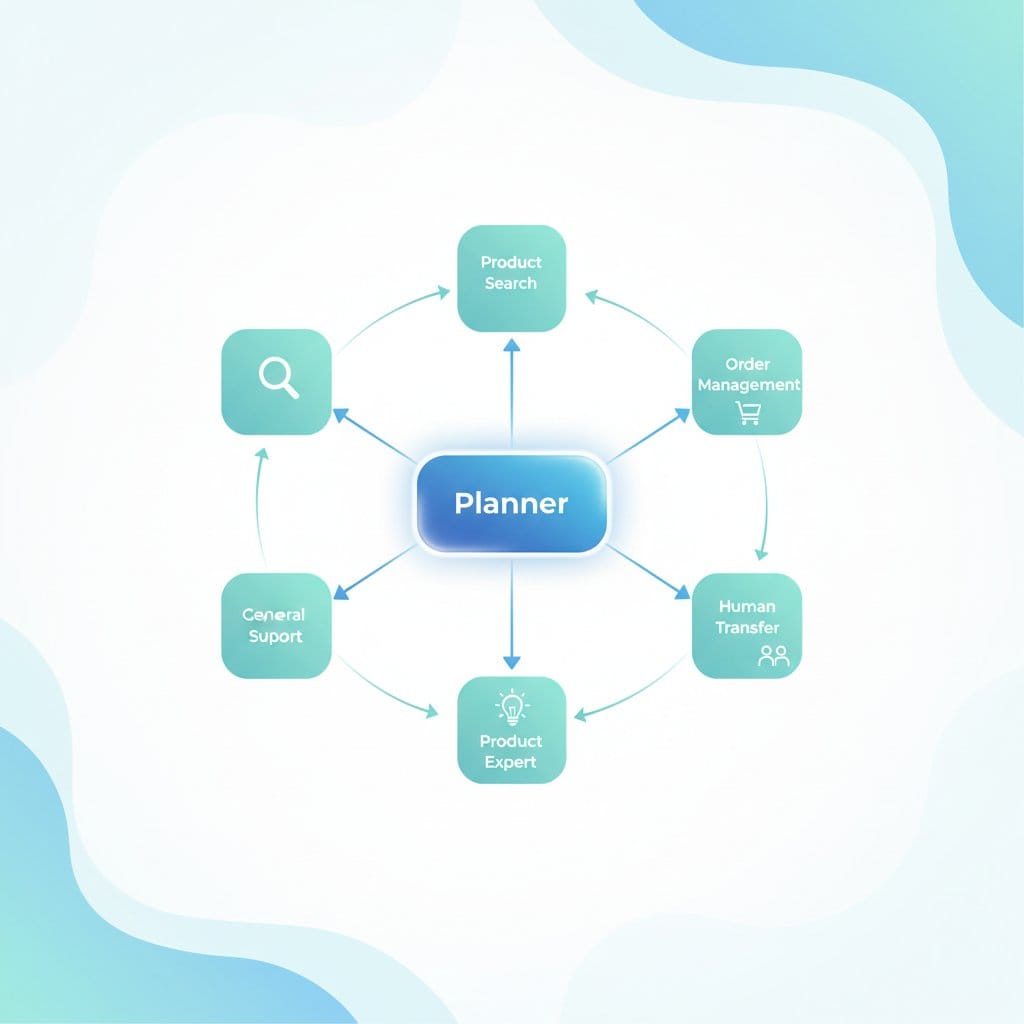
We replaced the monolithic pipeline with a multi-agent AI system. Each agent is a micro AI service among many services, specialized for a specific task, with its own model, tools, and knowledge base. A planning layer coordinates everything: deciding which agents to call, in what order, and whether the output meets the user's goal.
The architecture has three key components that work together for every user interaction.
Phase 1: Plan
When a user input arrives, it hits the PlannerAgent first. This agent doesn't answer the user directly. It applies reasoning and analysis to the query and creates an execution plan: an ordered list of agent tasks, each assigned to a specialized agent based on the input.
Say a customer writes: "I ordered a red jacket last week but it hasn't arrived. Can you also recommend matching shoes?"
The PlannerAgent breaks this into two tasks:
- OrderManagementAgent: Look up the order status for the red jacket
- ProductSearchAgent: Find matching shoes based on the jacket
Each task gets a specific sub-query so the downstream agent knows exactly what to handle. For simple queries like "what's your return policy?", the plan is just one task routed to the GeneralSupportAgent. We skip planning entirely when only one or two agents are registered, keeping overhead near zero.
Phase 2: Execute
The ChatOrchestrator executes the plan step by step. For each agent task, it:
- Retrieves only relevant context. A ProductSearchAgent gets product catalog data. An OrderManagementAgent gets order APIs. No agent drowns in irrelevant knowledge.
- Attaches the right tools. Each agent has access to its specific toolset: Shopify, WooCommerce, or Magento order APIs for order management; semantic search and taxonomy tools for product discovery; HubSpot or Klaviyo connectors for lead generation.
- Enables handoffs. Agents can transfer control to other agents mid-task when they hit something outside their scope.
- Streams the response. Users see tokens in real time, not a loading spinner followed by a wall of text.
This is where our architecture diverges most from standard RAG. Instead of one massive context window handling everything, each agent operates with a focused context: its own system prompt, its own retrieved knowledge, its own tools. The result is better accuracy, lower latency, and significantly lower cost per query.
Phase 3: Verify (Adaptive Replanning)
After each agent executes, the PlannerAgent switches to review mode. It evaluates what just happened and applies decision-making logic with one of three outcomes:
- CONTINUE: The task succeeded. Move to the next agent in the plan.
- COMPLETE: The user's goals are fully met. Stop execution.
- REPLAN: New information changed the situation. Generate a fresh plan.
Here's where this pays off. The OrderManagementAgent discovers the jacket order was actually cancelled, not delayed. The original plan to "recommend matching shoes" might not make sense anymore. The PlannerAgent can replan (up to 3 attempts), adapting to new information instead of blindly executing a stale plan.
If replanning exhausts its attempts, the system falls back to a RefusalAgent that provides a helpful response without crashing or hallucinating.
The Multi-Agent AI Ecosystem
We've built a growing roster of specialized agents. Each one has a focused job, its own tools, and its own retrieval requirements. Over time, agents learn from conversation patterns, and this continuous learning improves how they respond.
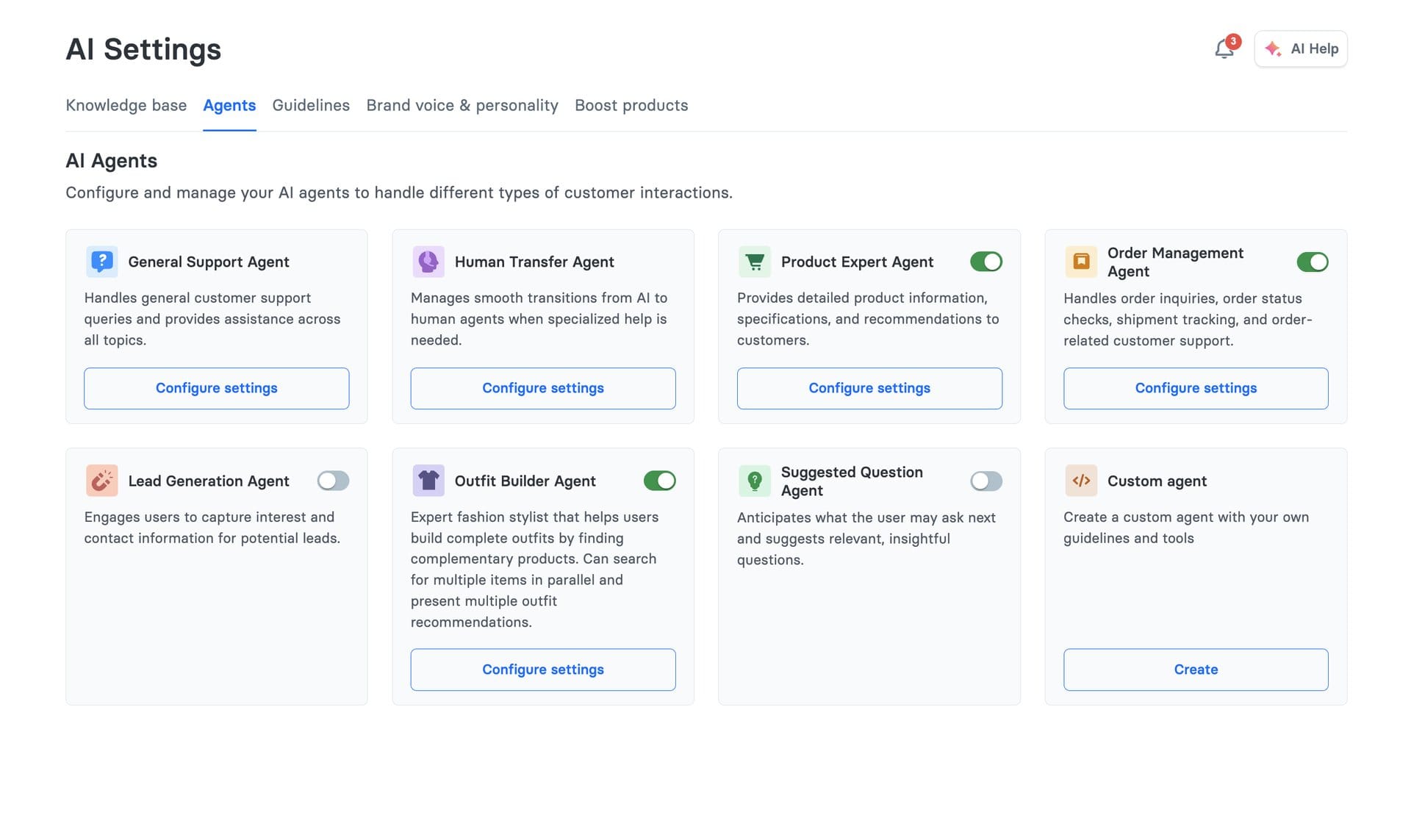
PlannerAgent routes queries to the right agents, reviews execution progress, and triggers replanning when needed. It has no tools of its own: pure routing logic.
ProductSearchAgent handles semantic product search with guided quiz capabilities. When a shopper says "I need a moisturizer for dry skin," this agent runs a conversational product discovery flow, narrowing options through follow-up questions.
ProductExpertAgent goes deeper: product comparisons, detailed recommendations, ingredient breakdowns. Brands like Tatcha use this to deliver expert-level beauty advice that drove a 3x conversion rate.
OrderManagementAgent connects to Shopify, WooCommerce, Magento, and Salesforce Commerce Cloud for order tracking, returns, and cancellations. It calls APIs directly instead of searching a knowledge base.
HumanTransferAgent handles the handoff to human support when the AI reaches its limits. No dead ends for the customer.
SocialReviewResponseAgent writes responses to Trustpilot and Feefo reviews, matching brand voice and addressing specific customer feedback.
Other agents include LeadGenerationAgent (captures leads into HubSpot/Klaviyo), VirtualTryOnAgent (visual try-on for fashion), SizingAssistantAgent (size recommendations), and OutfitBuilderAgent (complete outfit suggestions).
Each agent is independently configurable per brand. A fashion retailer enables VirtualTryOnAgent and OutfitBuilderAgent. A SaaS company might only need GeneralSupportAgent and HumanTransferAgent. Brands get exactly the agent types they need, each with a clear function, nothing more.
RAG Per Agent, Not Per System
One of the biggest wins of this architecture is how we handle knowledge retrieval. Instead of a single monolithic RAG pipeline, each agent declares its own retrieval requirements.
When the PlannerAgent creates a plan, the orchestrator kicks off parallel retrieval for all agents in the plan before any agent starts executing. By the time an agent is ready to run, its knowledge is already fetched and waiting.
The ProductSearchAgent retrieves from the product catalog and taxonomy. The GeneralSupportAgent retrieves from FAQs and knowledge bases. The OrderManagementAgent doesn't retrieve anything: it calls order APIs directly.
What this means in practice:
- Smaller, focused contexts. Each agent gets only what it needs, not everything the system knows.
- No wasted retrieval. We don't fetch product data for order queries or vice versa.
- Parallel fetching. Knowledge for all planned agents is retrieved concurrently, hiding latency behind execution time.
- Lower cost. Smaller contexts mean fewer tokens per call, which means lower LLM bills.
This is a direct improvement over traditional RAG where every query retrieves from every source. In our system, a simple order status check uses maybe 500 tokens of context. A product discovery query might use 3,000. Neither wastes tokens on irrelevant information.
Agent-to-Agent Handoff in Production
Real customer conversations rarely fit into a single agent's scope. We handle this through runtime handoffs, where one agent transfers control to another mid-conversation with full context preserved.
Common patterns we see in production:
- OrderManagement to HumanTransfer: The customer's order has a payment dispute or damaged item that requires human decisions.
- ProductSearch to ProductExpert: The customer needs deeper expertise beyond search results, like ingredient compatibility or fabric care.
- Any Agent to RefusalAgent: The query goes out of scope for the current agent's capabilities.
Handoffs are different from replanning. Replanning happens at the orchestrator level, where the PlannerAgent reviews the situation and creates a new plan. Handoffs happen at the agent level: one agent directly transfers control to another mid-task. Both mechanisms exist because conversations are unpredictable, and the system needs multiple ways to adapt.
For certain channels, we skip planning entirely and route directly. Trustpilot reviews go straight to the SocialReviewResponseAgent. Instagram comments route directly too. When a human agent is already present (Agent Assist mode), we exclude the HumanTransferAgent since escalation doesn't make sense. This direct routing cuts latency for known patterns and allows intelligent planning for ambiguous queries, improving outcomes across all channels.
What This Architecture Changed for Our Customers
Moving from monolithic RAG to a multi-agent planning architecture delivered real benefits for e-commerce brands.
Accuracy went up. Agents with focused contexts hallucinate far less than a single model juggling product data, order APIs, brand guidelines, and safety rules simultaneously. Our hallucination detection layer (built into the architecture) catches issues before they reach the customer.
Latency went down. Parallel retrieval plus smaller contexts means faster time-to-first-token. Simple queries skip planning entirely and hit a single agent in under a second.
Cost dropped. We're not stuffing every query with the entire knowledge base. Each agent uses only what it needs. For brands processing thousands of daily conversations, this adds up to meaningful savings.
Adding new capabilities became simple. New feature? Building a new agent is simple. New tool integration? Add it to an existing agent. The core orchestration doesn't change. When we built the OutfitBuilderAgent, it plugged into the existing system without touching the Planner or Orchestrator code.
Graceful degradation. If an agent fails, the system replans or falls back to RefusalAgent instead of returning an error. Customers never see a broken experience.
Per-brand customization. Each brand gets a different agent configuration. Fashion brands get outfit builders and virtual try-on. Beauty brands get product expert agents with ingredient knowledge. Everyone gets exactly the agents their customers need.
Brands like Puffy achieved 63% automated inquiry resolution with 90% CSAT. Manawa cut their workload by 43% and dropped response time from 40 minutes to 1 minute.
How This Compares to Industry Approaches
The multi-agent AI pattern is gaining traction across the industry. Microsoft, Google, and major AI labs have published orchestration patterns including planner-executor loops, hierarchical task decomposition, and tool-routing architectures.
What makes Alhena's approach different is that it's purpose-built for e-commerce. Generic agent frameworks handle general tasks. Our agents understand product catalogs, order lifecycles, return policies, and shopping behavior. The ProductSearchAgent doesn't just retrieve text; it runs guided product quizzes, understands taxonomy, and delivers product cards with images, prices, and ratings. The OrderManagementAgent doesn't just answer questions about orders; it calls external Shopify or WooCommerce APIs to pull real-time tracking data.
This specialization is why our agent architecture delivers results that generic multi-agent frameworks can't match out of the box. If you're exploring how agentic AI agents can drive revenue for your e-commerce brand (not just deflect tickets), check out our breakdown of how shopping AI agents fix the missing revenue layer in most e-commerce AI tools.
Ready to see the multi-agent architecture in action? Book a demo with Alhena AI or start for free with 25 conversations to experience the difference between a monolithic chatbot and a planning-first AI system.

Frequently Asked Questions
What is multi-agent AI architecture?
Multi-agent AI architecture is a system design where multiple specialized autonomous AI agents work together, each handling a specific task (like product search or order management). A planning layer coordinates which agents to call and in what order, instead of routing every query through a single monolithic pipeline.
How does the plan-execute-verify pattern work in AI agents?
The pattern has three phases. First, a PlannerAgent analyzes the user query and creates an ordered list of agent tasks. Then, each agent executes its task with focused context and tools. After each execution, the Planner reviews the result and decides whether to continue, complete, or replan with a new strategy.
Why is multi-agent AI better than RAG for ecommerce?
Standard RAG sends every query through the same retrieval pipeline, wasting tokens on irrelevant context. Multi-agent systems route queries to specialized agents that only retrieve what they need. This means lower latency, lower cost, and higher accuracy. For example, an order tracking query skips product catalog retrieval entirely.
How does Alhena AI use agent-to-agent handoffs?
Agents can transfer control to other agents mid-conversation when they hit something outside their scope. For instance, if an OrderManagementAgent discovers a payment dispute, it hands off to the HumanTransferAgent with full conversation context preserved. This ensures customers never hit a dead end.
What ecommerce platforms does Alhena's multi-agent system support?
Alhena's agents connect to Shopify, WooCommerce, Magento, and Salesforce Commerce Cloud for order management. For helpdesks, it integrates with Zendesk, Freshdesk, Gorgias, Gladly, Intercom, and Kustomer. Lead generation agents connect to HubSpot, Klaviyo, and MParticle.
How many specialized AI agents does Alhena use?
Alhena has over 15 specialized agents including ProductSearchAgent, ProductExpertAgent, OrderManagementAgent, HumanTransferAgent, SocialReviewResponseAgent, LeadGenerationAgent, VirtualTryOnAgent, SizingAssistantAgent, and OutfitBuilderAgent. Each brand enables only the agents relevant to their business.
Does the multi-agent architecture add latency compared to a single AI model?
Not significantly. The system starts retrieval for all planned agents in parallel before execution begins. Simple queries skip planning entirely and hit a single agent directly. Brands like Manawa dropped response times from 40 minutes to under 1 minute after switching to Alhena's multi-agent system.
How do I get started with Alhena's multi-agent AI for my ecommerce store?
Alhena deploys in under 48 hours with no dev resources needed. You can book a demo at alhena.ai/schedule-demo to see the multi-agent system in action, or sign up for 25 free conversations at alhena.ai/sign-up to test it on your store.