Latency Kill Conversions? Why Every Millisecond Matters in E-commerce CX
Every millisecond counts in e-commerce. Slow AI responses break trust and cost sales, while fast, sub-second replies boost conversions and customer satisfaction. Discover how Alhena AI turns speed into a competitive advantage for smarter, seamless shopping experiences.

Why Every Millisecond Matters in E-commerce
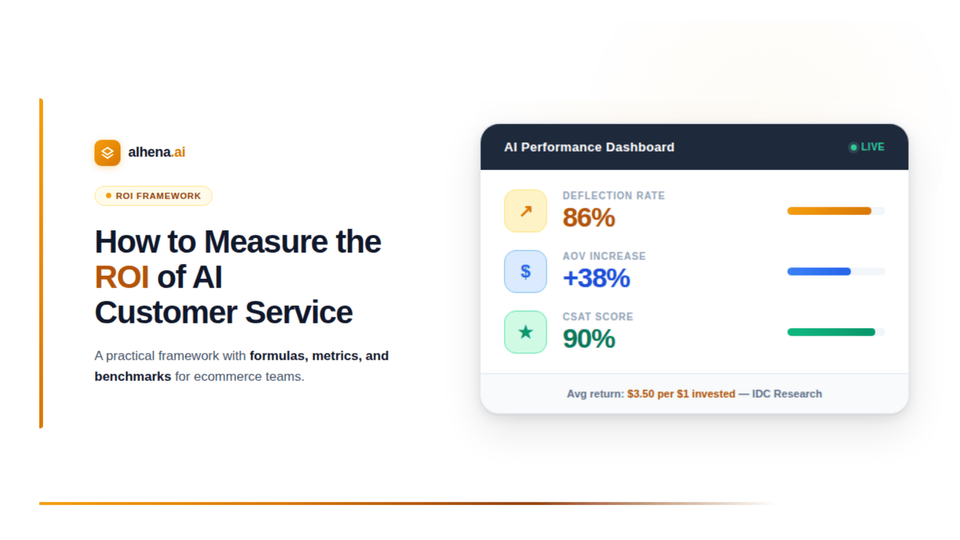
Amazon once found that every 100 milliseconds of delay could cost 1% in sales, a stat that still shapes performance benchmarks for modern digital commerce. Think about that for a second: a blink takes about 300ms, yet even a fraction of that can decide whether a shopper completes their purchase or abandons the cart.
We’ve all felt it. Imagine you’re in a checkout line at a store, and the cashier freezes for just a moment, customers shuffle impatiently, and some walk away. Online, that same pause is what we call latency, the time between a shopper’s action and your system’s response. On high-traffic days like Black Friday, those milliseconds become millions in lost revenue.
- Slow responses break the flow and increase frustration.
- Fast responses boost satisfaction, conversions, and trust.
- Even minor lags make a brand feel unreliable.
Now layer in the rise of AI shopping assistants and chatbots. Today, shoppers expect instant answers about shipping, returns, or product details. If the AI stalls, the customer’s experience breaks. If it responds in under a second, it feels natural, smooth, and trustworthy, exactly the kind of interaction that drives higher conversions and repeat purchases.
Fast AI assistants:
- Power conversational search and instant recommendations
- Trigger real-time nudges and promotions
- Support in-chat checkout and personalization
- Handle holiday-scale surges without delay
That’s why Alhena AI’s architecture is engineered for sub-second response times, measured across every stage of the pipeline.
End-to-end latency includes:
- Model inference – time for the AI to generate tokens
- Network – DNS, TLS, and transit between servers
- Front-end rendering – DOM updates and UI paint
Common bottlenecks and solutions
- Token streaming: optimize Time to First Byte (TTFB), use server-side streaming, and cache system prompts.
- Server load: pre-warm instances, autoscale GPUs/CPUs, and monitor P95/P99 response times.
- Network hops: minimize middleware layers, use HTTP/3, co-locate edge servers, and batch API calls.
By continuously monitoring TTFB, time-to-first-token, and p95 response times, Alhena AI ensures that latency never disrupts a shopper’s flow. Because in e-commerce, speed isn’t optional; it’s the foundation of trust and conversion.
At Alhena AI, we see this every day: speed isn’t just technical performance; it’s customer psychology at scale. And in e-commerce, milliseconds aren’t small; they’re everything.
The Psychology of Speed in Shopping
Modern shoppers don’t go online hoping for patience; they expect instant gratification. In fact, our digital patience has been shrinking year after year. What used to feel acceptable at three seconds now feels frustrating at one.
On mobile devices, the stakes are even higher. Why? Because the human brain equates speed with competence and trust. In e-commerce, that means every millisecond shapes how shoppers feel about your brand, not just how they interact with it.
Slow responses make brands feel unreliable and disconnected.
- 12% of U.S. consumers cite slow replies as their biggest support frustration.
- Fast replies, by contrast, improve satisfaction and signal operational excellence.
Alhena AI helps brands stay “always-responsive,” cutting Time to First Response to under a second across chat, mobile, and web, ensuring the brand always feels awake, attentive, and trustworthy.
This is why speed isn’t just a technical metric; it’s a psychological trigger. Two cognitive biases explain why fast AI feels more trustworthy:
- Fluency Heuristic: The brain trusts what feels effortless. Instant responses feel “more correct,” which increases confidence in AI suggestions.
- Instant Gratification Bias: The quicker the reward, the stronger the emotional satisfaction, reinforcing loyalty and repeat purchases.
When an AI shopping assistant like Alhena AI, a sub-second conversational design, blends cognitive psychology and engineering speed to make every chat feel natural, fluid, and human.
The Hidden Cost of AI Latency
We’ve all been there. You’re chatting with a support agent online, and you ask a simple question, “What’s your return policy?” And then… silence. Five seconds tick by. Ten seconds. Suddenly, the smooth shopping experience feels broken. In e-commerce, that pause is expensive.
Every delay compounds across thousands of customer interactions. What seems like a small lag can quietly erode key business metrics:
When an AI assistant lags, it breaks conversational flow. Each second of delay adds friction, leading to:
- Broken engagement loops
- Eroded confidence
- Abandoned carts
Alhena AI eliminates these hidden costs with sub-second response times designed for real-time commerce. Its architecture continuously monitors:
- FRT (First Response Time) and ART (Average Response Time)
- p95/p99 latency during peak load
- Edge node performance and autoscaling under stress
By combining fast inference, edge caching, and intelligent routing, Alhena AI ensures shoppers never hit that moment of doubt. Conversations stay instant, human-like, and seamless even during flash sales or global peaks. Speed isn’t just a UX metric; it’s a revenue multiplier. The faster your AI responds, the higher your CSAT, NPS, and customer loyalty climb.
Inside the AI Engine
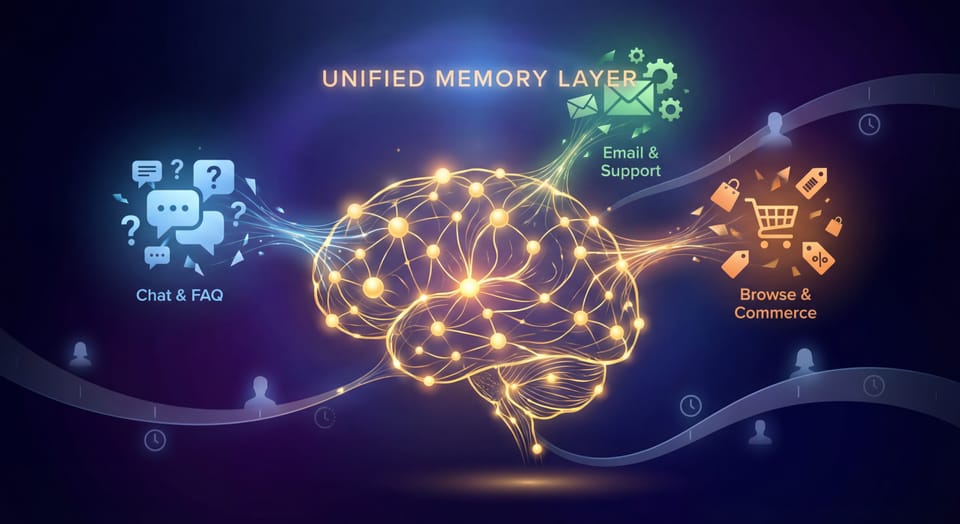
Delivering answers in under a second doesn’t happen by accident; it’s engineered. Every interaction you see on the surface depends on a finely tuned chain beneath it, from how data is chunked to where it’s served from.
- Chunking & embeddings: Alhena uses agentic chunking. Think of it like running a bookstore: if the books are scattered in piles, finding the one title you need could take forever. But if everything is neatly organized by category, author, and index cards, you can grab the right book in seconds. Breaking data into semantically coherent pieces. This ensures the system retrieves only the most relevant chunks, cutting context assembly time and boosting answer precision. Each chunk is vectorized using FAISS-based semantic search, allowing instant nearest-neighbor retrieval.
- Edge deployments & caching: Instead of sending every query to a single cloud hub, Alhena uses edge inference nodes and Redis-based caching. It’s like stocking local warehouses instead of shipping everything from a single central hub. The result? Responses reach users 30–40% faster while reducing bandwidth and latency spikes.
- Stress-testing for surges: During Black Friday or flash sales, a slow or overloaded assistant in those moments can mean thousands of abandoned carts. Millions of queries can hit at once. Many bots “choke” under pressure, but Alhena AI is built to stay steady. t uses real-time load forecasting, autoscaling compute, and response caching to handle millions of concurrent interactions without breaking conversational flow.
- Asynchronous handoffs: AI-to-agent or agent-to-agent transitions happen without blocking the session, so conversations continue seamlessly. This ensures consistent low-latency interactions, even when human agents step in.
Alhena AI continuously monitors and optimizes to keep AI lightning fast:
- TTFT (Time to First Token): Time from request to first generated word benchmarked under 100 ms.
- End-to-end latency: Total time from user input to visible reply, measured across model, network, and front-end layers.
- Autoscaling: Predictive scaling prevents cold starts during traffic surges.
- Parallelized I/O: Database calls, API lookups, and embedding retrievals run concurrently to reduce wait time.
- Context trimming: The model sends only relevant history to reduce token overhead.
Edge vs. cloud response: Traditional cloud inference sends every request to centralized servers, adding network hops. Edge deployment, however, runs models closer to users, improving compliance (e.g., GDPR), boosting reliability, and lowering latency. Alhena’s hybrid edge-cloud model ensures that response time stays below one second globally, even as query volume spikes.
In other words, speed isn’t an accident; it’s engineered. And in e-commerce, speed under pressure matters just as much as speed on an average day. Alhena is built for both. Alhena AI turns milliseconds into momentum. Every optimization, from embeddings to edge inference, exists for one purpose: to make every customer interaction instant, intelligent, and human-smooth.
What Fast AI Looks Like in Practice
Picture this: a shopper is ready to buy but hesitates at checkout. They open the chat window and ask, “When will my order arrive?” With a traditional bot, they might wait a few seconds, wonder if the system even understood, and leave.
Now imagine the same moment powered by Alhena AI: the response appears in under a second: clear shipping details, no hesitation, and no broken flow. The shopper trusts the answer, completes the purchase, and walks away with a positive impression of the brand.
To shoppers, it feels instant, almost predictive.
- No waiting or loading anxiety
- Smooth, uninterrupted back-and-forth
- Higher confidence to add to cart or complete checkout
In cognitive terms, sub-second latency keeps users in a “flow state”, preventing decision fatigue. Every instant answer sustains trust and momentum.
Fast, intelligent AI interactions reduce friction and encourage deeper engagement:
- Fewer drop-offs: Instant replies resolve purchase blockers like size, stock, or returns.
- Smarter upsells: Real-time product comparisons and recommendations increase AOV.
- Timely nudges: Detects hesitation and triggers contextual offers before abandonment.
- Personalized journeys: AI learns context with every message, making each interaction more relevant.
A leading DTC skincare brand saw a 14% increase in checkout completion after optimizing latency with Alhena AI. Instant responses didn’t just make the chat smoother; they made customers feel seen, heard, and supported.
Alhena’s latency pipeline is built for speed:
- 0.12s vector search (semantic retrieval using FAISS)
- 0.08s model inference (optimized transformer responses)
- 0.3s total render (client-side hydration and delivery)
Together, these engineering optimizations ensure that every customer interaction feels instant, intelligent, and human. Fast AI doesn’t just serve information; it creates micro-moments of trust that turn browsers into buyers and one-time shoppers into loyal customers.
The AI Latency Playbook for E-commerce
So, how fast should an AI shopping assistant be? The benchmark is clear: under one second. Anything slower adds friction, erodes trust, and risks lost revenue.
E-commerce brands can test and monitor latency using a mix of synthetic monitoring and real user data to ensure sub-second experiences. Run scheduled web/API tests from multiple regions to measure TTFB, DNS, and TLS performance, while Real User Monitoring (RUM) tools track FCP, LCP, and TTI across devices.
Continuously monitor API latency (P50/P95/P99) for key flows like search, cart, and checkout, and test CDN and edge cache hit ratios to detect regional slowdowns. Finally, perform load and spike tests before peak traffic and set alert thresholds and SLAs to catch regressions early. With Alhena AI’s real-time analytics, brands can maintain lightning-fast response times and optimized AI chatbot latency across every shopper interaction.
Here’s a quick checklist for ecommerce brands:

1. Measure:
Track latency at every layer from Time to First Token (TTFT) to full page render.
- Metrics: TTFB, LCP, CLS, P50/P95/P99 API latency, cache hit ratio
- Tools: Lighthouse, WebPageTest, Datadog RUM, Prometheus, Grafana
- Coverage: search → PDP → cart → checkout
2. Benchmark:
Set clear SLOs to match industry leaders.
- Chat response (p95) < 1s
- API latency (p95) < 300ms
- LCP < 2.5s across devices
- Compare new releases vs. top-quartile performance
3. Optimize:
Cut latency where it counts.
- Use CDN and edge caching to bring data closer to shoppers
- Enable HTTP/3 and compression (Brotli/Gzip)
- Cache high-traffic prompts and common AI responses
- Streamline payloads and parallelize I/O for faster fetches
4. Stress-Test:
Prepare for peak days like Black Friday.
- Load-test using k6, Gatling, or JMeter
- Simulate traffic spikes and monitor CPU, memory, and queue depths
- Set alerts for p95/p99 latency regressions
Faster AI doesn’t just “feel” better, it proves better.
- Higher conversions: +300% average lift through instant, intent-aware chat
- Higher AOV: +15–20% growth via real-time personalization
- Lower abandonment: Up to 25% of lost carts recovered via proactive nudges
Alhena AI delivers these results with sub-second performance, advanced monitoring, and self-optimizing infrastructure designed for speed under scale. At the end of the day, speed isn’t just a technical KPI; it’s a revenue driver. The faster your AI responds, the faster your business grows.
Helpful Read: Implementing GenAI
Conclusion: How Alhena AI Redefines the future of CX
In e-commerce, milliseconds equal money. Latency isn’t just a delay; it’s a silent leak in revenue, trust, and brand loyalty. Every second of lag inflates cart abandonment and erodes customer confidence.
That’s why Alhena AI is engineered for lightning-fast, sub-second performance for the next generation of customer experience (CX). Ensuring real-time conversations stay fast, natural, and reliable. Its edge architecture, caching, and continuous retraining keep latency low even at scale.
Speed now defines great customer experience; it drives higher CSAT, NPS, and conversions across every channel. In short, fast AI builds loyal customers, and Alhena AI ensures your brand never misses a millisecond.