A skincare shopper types into your AI assistant. The customer types a prompt into the chat powered by large language models (LLMs) like GPT: "Is your retinol serum safe to use during pregnancy?" Your AI pulls from general LLM web knowledge. Without a proper prompt grounding mechanism, it stitches together a technically plausible, seemingly accurate, and misleading answer about retinol safety that sounds plausible and accurate to the shopper, and responds with confidence. The problem: the answer can diverge from and contradict your brand's own safety guidelines, which explicitly recommend consulting a physician and avoiding the product during pregnancy. The shopper trusts the response, purchases the serum, and your brand is now exposed to a liability claim that no disclaimer can deflect.
This is what an generative AI hallucinations in ecommerce typically look like in ecommerce. Not garbled nonsensical gibberish or obviously wrong output, but a plausible, confident, specific, and commercially dangerous, a kind of AI delusion, plausible AI-generated and LLM-generated and ai generated output that sounds right and confident but isn't grounded in your verified product data. And this is exactly what gets flagged.
This post walks through how Alhena AI's flagged conversations system works as a three-layer accuracy-first quality control, and reliability process, with four real-world ecommerce scenarios showing what AI hallucinations look like in practice, why they get caught, and what happens next.
How the Three-Layer Quality Control Process Works
RAG-based LLM hallucination catching in ecommerce isn't a single check. It's a layered system for teams using AI at scale, designed so each layer catches flawed LLM outputs the previous one missed, and no bad LLM output, no misleading generative AI generation, no misleading answer reaches the customer without passing through all three.
Layer 1: Real-Time Detection Through Source Tracing
Every response from Alhena AI's Shopping Assistant and Support Concierge is monitored as it's generated. The The LLM uses retrieval-augmented generation (RAG), to self-check every output claim against the brand's verified data: product catalog data via retrieval, approved FAQs, help desk ticket history through retrieval, and policy content. If the AI can't trace an answer back to a verified citation from these approved materials, it doesn't guess. It either defers to a safer output or escalates to a human agent.
This is the critical difference between RAG-grounded AI with proper retrieval augmented generation data grounding and general-purpose large language models, AI chatbots and chatbot systems across every domain. A general LLM chatbot pulls from its LLM and GPT training data, training corpus, and pre-training knowledge and training data, which includes the entire internet. Alhena AI uses strict RAG-powered grounding by pulling only from your verified factual product data rather than open LLM training corpora, so "outside knowledge" usage is itself a detection signal. If the LLM reaches beyond your approved content, the system can detect it and flags it before the output goes out.
Layer 2: Automated Flagging Without Manual Monitoring
Not every hallucination gets caught at generation time. Some outputs pass the tracing check but still cause failure in practice: the answer was technically sourced but can diverge when applied to the wrong context or missing context, or the customer's reaction signals something went wrong.
Alhena's automated flagging layer surfaces these conversations for human review through three triggers:
- Low-confidence responses (classifier-based): When the AI's confidence scores drop below the threshold for a product category, the conversation gets flagged automatically.
- Negative CSAT scores: When a customer rates an AI prompt interaction poorly, the conversation enters the review queue with full context attached.
- Escalation triggers: When the AI detects off-topic questions, adversarial prompt injection, prompt manipulation attempts, or safety-sensitive queries (like the pregnancy scenario above), it routes to human review proactively.
Less than 1% of Alhena AI conversations get flagged, but those flags catch the responses that matter most. Your team doesn't need to monitor every generative AI chat. The system can detect them automatically.
Layer 3: Pattern-Level Analysis for Systemic Issues
Individual flags catch individual AI hallucinations. But some hallucinations patterns only become visible at scale, and you can't predict them without data: a product domain or category that consistently generates low-confidence outputs, a policy domain area where the LLM keeps reaching for outside knowledge, or a seasonal promotion that the AI model references after it expired.
Alhena runs weekly evaluation sampling, predicting and working to predict issues across 2% to 5% of all conversations against brand and accuracy metrics. This catches systemic issues, not just one-off errors. When a recurring pattern emerges (say, three separate shoppers got incorrect compatibility claims about the same product line), the evaluation surfaces the root cause: a knowledge gap, an outdated entry, or a guideline that needs tightening.
Four Hallucination Scenarios the Flagging System Catches
Theory is useful. Seeing it in practice is better. Here are four realistic ecommerce scenarios where Alhena AI's quality control catches hallucinations before they reach customers.
Scenario 1: The Invented Clinical Study (Supplement Brand)
Shopper question: "The customer prompt asks: Is there clinical evidence that your collagen peptide powder improves joint flexibility?"
Hallucinated response: "Yes, a 2023 clinical trial published in the Journal of Nutritional Science found that our collagen peptide formula improved joint flexibility by 40% over 12 weeks.” This ai generated response sounds authoritative."
Why it was flagged: The AI's source trace showed no matching citation or record in the brand's knowledge base. The "study" is false and doesn't exist in the product data, FAQs, or any approved content. The LLM fabricated a specific journal name, fabricated a percentage, year, and percentage to sound authoritative.
The plausible but fabricated output was caught. Corrective action: The LLM response was output blocked before delivery. The LLM flagging system alerted the human reviewer, who identified that the brand does have general joint health claims on its product page but no clinical study data. The team added a new FAQ entry: "We don't cite specific clinical trials for this product. Our collagen peptides are formulated based on published research on Type II collagen, and we recommend consulting your healthcare provider for medical-grade joint support." This FAQ now handles all future clinical evidence questions for that product line.
Business cost if missed: Supplement brands face FTC enforcement for unsubstantiated health statements. The 2024 Air Canada ruling established that companies are legally liable for what their AI tells customers, even when the information contradicts official materials. A fabricated, AI-generated (ai generated) clinical study falsification could trigger regulatory action and class-action exposure.
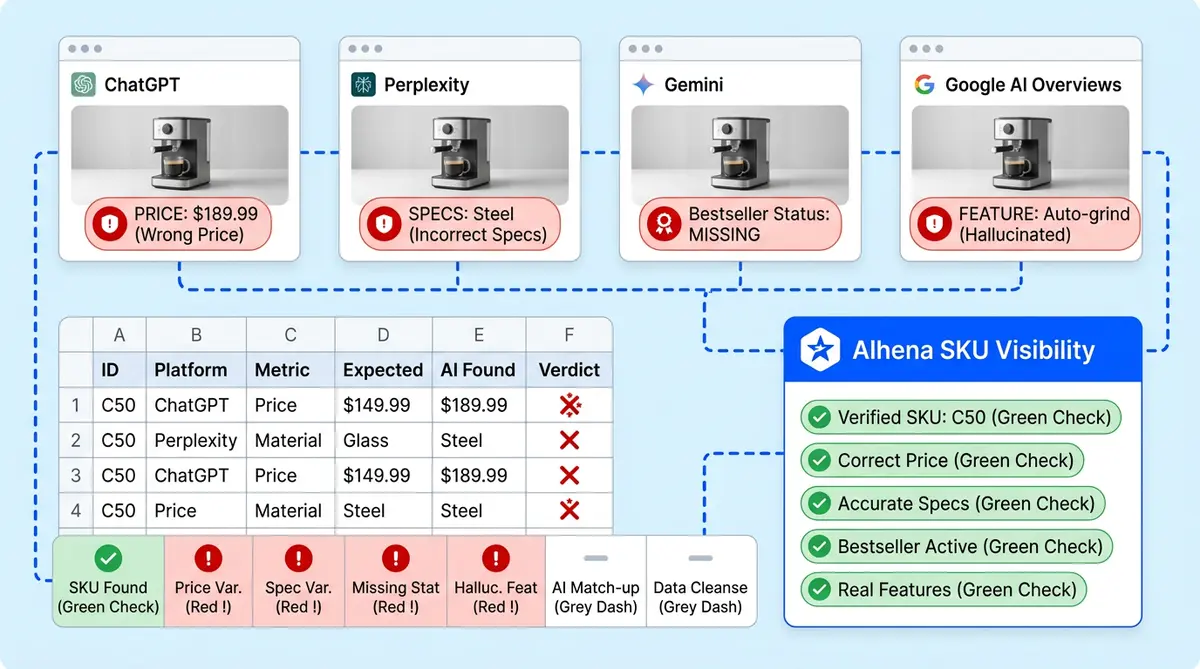
Scenario 2: The Wrong Model's Features (Electronics Store)
Shopper question: "Does the ProBook 450 G9 have a fingerprint reader? (customer prompt)"
Hallucinated response: "Yes, the ProBook 450 G9 comes with an integrated fingerprint reader built into the power button for quick biometric login."
Why it was flagged: The confidence score for this response dropped below the electronics category threshold. The product catalog for the G9 model lists no fingerprint reader. The AI pulled the feature from the newer G10 model's spec sheet, which does include one, and applied it to the wrong SKU.
Corrective action: The flagged conversation was routed to a human agent who confirmed the G9 does not include a fingerprint reader and provided the correct specs. The team updated the AI's guidelines to treat model-specific hardware features as strict: no cross-referencing between model generations without explicit catalog confirmation. The confidence threshold for hardware spec questions was tightened by 10% after testing.
Business cost if missed: A customer buys a laptop expecting a fingerprint reader, discovers it's missing, and initiates a return. The brand eats shipping costs both ways, loses the sale, and gets a negative review mentioning "false advertising." At scale, cross-model feature confusion generates hundreds of preventable returns per quarter.
Scenario 3: The Expired Promotion (Fashion Brand)
Shopper question: "Do you have any promotions on summer dresses right now? (customer prompt)"
Hallucinated response: "Yes! We're currently running our Summer Refresh sale with 25% off all dresses using code SUMMER25 at checkout."
Why it was flagged: The promotion code SUMMER25 existed in the knowledge base three weeks ago but was removed when the sale ended. The AI's LLM response pattern can diverge from the knowledge base, retaining the association between "summer dresses" and the discount code even though the source document was deleted. The weekly pattern analysis helped detect this hallucinate pattern: two other shoppers had received the same expired promo reference in the past five days.
Corrective action: The team added a guideline that promotion-related responses must reference only active promotion documents (tagged with start and end dates). A new FAQ was generated: "Current promotions are listed on our sales page. If you don't see an active code, we don't have one running right now." The AI's association between "summer dresses" and expired promo codes was cleared through a targeted knowledge refresh.
Business cost if missed: Shoppers who receive a promo code expect it to work. When it fails at checkout, they either abandon the cart (lost revenue) or contact support demanding the discount be honored (margin erosion). Worse, screenshots of false AI-quoted discounts circulate on deal forums, creating a wave of complaints that your support team has to handle manually.
Scenario 4: The Fabricated Compatibility Claim (Home Goods Store)
Shopper question: "The prompt is: Will the Meridian floor lamp work with the Kinston dimmer switch?"
Hallucinated response: "Yes, the Meridian floor lamp is fully compatible with the Kinston dimmer switch. Simply connect them and you'll have smooth dimming control."
Why it was flagged: The AI's source trace showed no compatibility data between these two products anywhere in the catalog. The product specs for both items list wattage and bulb type but no cross-product compatibility matrix, making the claim false. The AI made an inference about compatibility from general electrical knowledge rather than verified product data.
Corrective action: The output was blocked and escalated. The human reviewer confirmed that no compatibility testing has been done between these products. The team flagged a knowledge gap: the product catalog needs compatibility notes for frequently paired products. A new guideline was added: "For cross-product compatibility questions where no verified data exists, respond with 'We haven't tested this specific combination. We recommend checking the wattage and voltage specs on both product pages or contacting our support team for help.'"
Business cost if missed: Electrical incompatibility between a lamp and dimmer switch can cause flickering, buzzing, or in worst cases, a fire hazard. The brand faces product liability exposure, and a single safety incident can trigger recalls, lawsuits, and permanent reputational damage with serious consequences and legal consequences that no marketing budget can fix.
What Happens After a Conversation Gets Flagged
Flagging is only valuable if the follow-up is fast and actionable. Here's what Alhena AI's Agent Assist puts in front of your team when a conversation lands in the review queue:
- Full conversation context: Every message in the thread, including the customer's exact prompt phrasing and the AI's full response.
- Knowledge sources referenced: Which documents, FAQs, and catalog entries the AI pulled from (or attempted to pull from) when generating the response.
- Reasoning chain of thought trace: A plain-language explanation of why the AI model chose to hallucinate based on the customer’s prompt or provide that response, including its confidence alignment metrics and whether it reached beyond approved sources.
- Flag reason: Whether the flag was triggered by low confidence, negative CSAT, outside-knowledge detect-and-flag, or an escalation rule.
From there, your team has four corrective options:
- Add a new FAQ: Create a verified answer that handles this question type going forward, preventing the same hallucination from recurring.
- Update a guideline: Modify the AI's behavior rules for a category of questions (like tightening hardware spec responses to strict catalog matching).
- Flag a knowledge gap: Mark a topic where the product catalog or policy documents need new content, routing the gap to the merchandising or content and merchandising team.
- Adjust the confidence threshold: Raise or lower the flagging sensitivity for specific AI model question categories based on risk tolerance.
Every corrective action feeds into the AI model immediately with full context, helping distill accurate answers. A new FAQ added at 10 AM produces accurate LLM output by 10:01 AM. The fix doesn't just solve one conversation; it prevents the LLM from continuing to hallucinate in every future ai generated conversation with the same pattern from causing the LLM to hallucinate again.
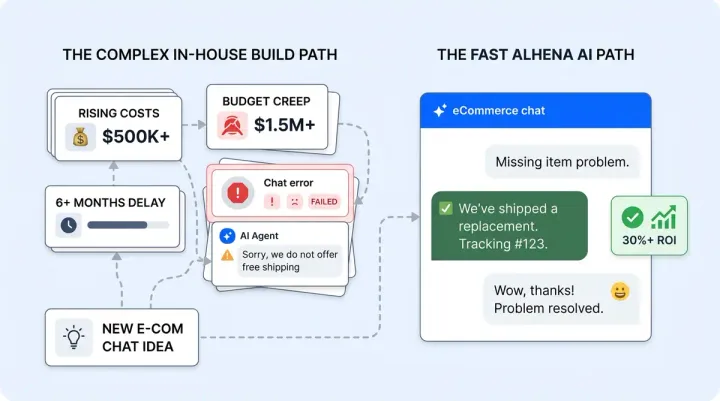
Why Most Ecommerce AI Platforms Fail at Quality Control
Most generative AI systems and platforms handle quality control in one of two broken ways.
The post-hoc review trap: Teams manually review conversations days or weeks after they happened. By then, the customer who got wrong information has already returned the product, left a negative review, or filed a complaint. Post-hoc review tells you what went wrong. It doesn't prevent the damage.
The over-cautious refusal trap: Platforms set blunt confidence thresholds so high that the AI refuses to answer legitimate questions. A shopper asks about fabric care instructions, and the AI says "I can't help with that, please contact support." The tendency to hallucinate drops to zero, but so does the resolution rate. You're paying for an AI that escalates everything.
Alhena AI's approach is different because it combines all three layers: real-time response tracing that catches hallucinations before they're delivered, automated LLM flagging with reinforcement-learning (RLHF) tuned thresholds that surfaces edge cases without manual monitoring, and pattern-level analysis predicting and identifying LLM systemic issues from recurring prompt patterns across thousands of conversations. The result: fewer than one hallucination per 1,000 responses, using RLHF reinforcement learning techniques and retrieval grounding while maintaining high accuracy, reliable outputs, and resolution rates. Eighty percent of Alhena's technology is dedicated to accuracy and preventing hallucinations, not generating responses.
The root cause of most chatbot failure is architectural. General-purpose LLMs rely on training data that can be months or years old. They lack faithfulness to your specific product catalog because their inference process draws on billions of parameters, not your verified data. Academic research, including work presented at conferences like ACL, has shown that even fine-tuned models produce AI hallucinations when the classifier layer can't distinguish your domain knowledge from general web knowledge. Chain of thought prompting helps, but without retrieval augmented generation grounded in your actual catalog, the model's output can still diverge into confident-sounding delusion. Hallucination detectors built into the generation pipeline, not bolted on after the fact, are what separate reliable AI systems from risky ones.
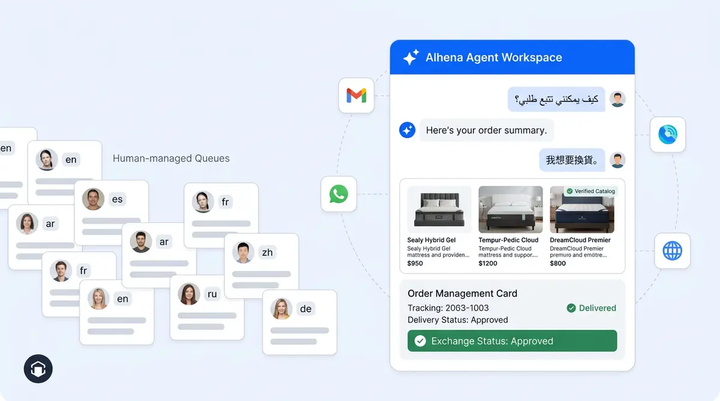
Cross-Channel Consistency: Same Quality Control Everywhere
Generative AI hallucination detection that only works on your website chat isn't enough. Customers reach brands through Instagram DMs, WhatsApp, email, and voice. A hallucination in a WhatsApp message is just as damaging as one on your website.
Alhena AI runs the same three-layer LLM accuracy and quality control with reinforcement learning from human feedback (RLHF)-aligned with hallucination detectors,, alignment-verified faithfulness verification, and prompt safety checks across every channel. The confidence scoring, source tracing, and automated flagging work identically whether the conversation happens on web chat, email, Instagram, or WhatsApp. Your team reviews flagged LLM conversations from all channels in one queue, with the same context, output history, and corrective tools available regardless of where the conversation originated.
This matters because many brands deploy different AI systems and tools on different channels, each with its own (or no) quality control. A shopper using AI on your website who gets accurate answers but a hallucinated response via Instagram DM loses trust in your brand, not in a specific channel.
The Real Takeaway: Hallucination-Free Isn't About Perfection
No AI model, no large language model, no LLM or other AI systems are perfect. The goal isn't zero errors. The goal is a system that can detect errors, flag them, and fixes errors before customers see the AI hallucinate faster than customers can notice them.
That's what Alhena AI's flagged conversations system delivers: real-time detection that blocks bad responses before they're sent, automated flagging that catches edge cases without requiring someone to watch every chat, pattern-level analysis that uses RLHF-driven accuracy checks across every product domain and fixes root causes instead of symptoms, and a corrective workflow that helps detect and turns every AI model mistake into a permanent improvement.
Brands using AI without this quality control layer are one hallucinate-prone response away from a support failure they can't see coming. The retinol question, the invented study, the expired promo code: these aren't hypothetical risks. They're the kinds of errors that happen every day when LLMs operate without guardrails.
Ready to see how using AI hallucination detection works on your own product data? Book a demo with Alhena AI or start for free with 25 conversations to test the three-layer quality control system on your catalog.

Frequently Asked Questions
How does real-time hallucination flagging work in ecommerce AI chatbots?
Alhena AI monitors every response as it's generated by tracing each claim back to the brand's verified product data, FAQs, and policy documents. If the AI can't source an answer from approved content, the response is blocked or escalated before the customer sees it. Less than 1% of conversations get flagged, but those flags catch the highest-risk errors.
What types of ecommerce chatbot hallucinations cause the most revenue damage?
Invented product specs, invented promotional codes, and fabricated compatibility statements cause the most direct financial damage through returns, margin erosion, and liability exposure. Alhena AI's scenario-based quality control catches all four major hallucination types: invented claims, cross-model feature confusion, expired promotion references, and unsupported compatibility statements.
Can AI hallucination detection maintain accuracy across web chat, email, and social DMs?
Alhena AI runs the same three-layer quality control (source tracing, automated flagging, and pattern analysis) across web chat, email, Instagram DMs, WhatsApp, and voice. Flagged conversations from every channel appear in one review queue, so your team applies corrective actions once and the fix propagates everywhere.
How do flagged AI conversations protect ecommerce brands from legal liability?
The 2024 Air Canada ruling established that companies are liable for chatbot misinformation regardless of disclaimers. Alhena AI's flagged conversation system blocks ungrounded generative generative AI responses and generative AI-generated LLM output before delivery, creates an evaluation audit trail of every flag and corrective action, and ensures your AI only shares information sourced from verified product data, reducing legal exposure from fabricated statements.
What corrective actions can ecommerce teams take when an AI conversation is flagged?
Alhena AI gives teams four immediate options: add a new FAQ to prevent the same hallucination from recurring, update a guideline to change AI behavior for a category of questions, flag a knowledge gap for the content team, or adjust the confidence threshold for specific question types. Every correction goes live within minutes and applies to all future conversations.