Most Ecommerce Teams Are A/B Testing the Wrong Things
Ecommerce brands spend thousands of hours testing button colors, hero banners, and checkout page layouts. Meanwhile, the channel delivering 4x higher conversion rates than unassisted browsing sits untouched: the AI chatbot. According to Adobe Analytics data, AI powered shopping assistants convert visitors at 13.8% compared to 3.4%, outperforming any ad channel for everyone else. Yet most marketing teams, CX leaders, and marketers treat their chatbot as a static feature, not as the high-leverage ai ab testing ecommerce opportunity it actually is.
This guide is your conversion rate optimization playbook for chatbots. Conversion rate optimization for AI chatbots. It breaks down exactly what to test inside your AI chatbot, how to analyze and measure results without falling into statistical traps, and how the best brands optimize their ai experimentation programs to move revenue, customer experience, and conversion rate optimization, not just CSAT scores.
Why AI A/B Testing Differs from Traditional CRO
If you've run A/B tests on landing pages, you already know the basics: split traffic, change one variable, measure the outcome. Chatbot testing can help apply the same principle but adds layers of complexity that trip up even experienced CRO teams running multivariate testing or split testing campaigns.
The Conversation Variable Problem
On a landing page, every visitor sees the same headline. In a chatbot conversation, every visitor types something different. The AI responds differently each time, even to similar questions, because large language models generate probabilistic outputs. Your "Variant A" isn't truly static the way a landing page variant is.
Traditional A/B tests measure single interactions (a click, a form submission). Chatbot tests measure multi-turn conversations where each message builds on the last. A greeting change might look neutral at the message level but compound into a 27% lift in qualified leads over a full conversation, as one SaaS company documented, for example.
Lower Volume, Longer Test Cycles
Your product pages might get 50,000 views per week. Your chatbot might handle 2,000 conversations in the same period. That smaller sample size means you need to run tests for 4 to 8 weeks instead of days. Stopping early is the single most common mistake that prevents teams from being able to optimize effectively: nearly 40% of A/B experiments are stopped prematurely, according to Nielsen Norman Group.
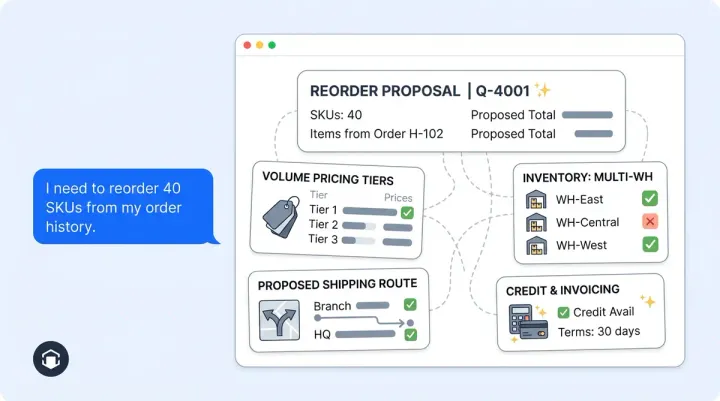
Plan for a minimum of 1,000 conversations per variant before drawing conclusions. If your chatbot handles fewer than 500 conversations per month, focus on getting your baseline right before running split tests.
Seven High-Impact Chatbot Tests That Actually Move Revenue
Not all chatbot tests are created equal, and multivariate testing principles apply here too. Here are seven test categories, each with a concrete example that consistently produce measurable revenue impact, ranked by typical lift size.
1. Greeting Messages: The Highest-ROI Test You Can Run
Your chatbot's first message sets the trajectory for the entire conversation. Testing greeting variations through split testing is low-effort and high-reward, easy to optimize. The data can help prove this: personalized greetings that clearly state a benefit capture 28% more leads than generic "How can I help you?" openers, according to Builtabot's research.
Test these variations:
- Generic vs. behavioral triggers ("Hi there!" vs. "I noticed you're comparing two moisturizers. Want help picking one?")
- Question vs. benefit framing ("Need help?" vs. "I can find your perfect size in 30 seconds")
- With vs. without quick-reply buttons (adding buttons drives 3x higher completion rates)
One fintech company tested switching from "Need help?" to "Get your free guide before you go" on exit intent and recovered 12% of abandoning visitors.
2. Response Tone and Personality
The same product recommendation lands differently when delivered in a formal corporate tone vs. a friendly conversational one. Research published in the Journal of Retailing and Consumer Services found that informal chatbot language increases brand affinity through what psychologists call parasocial interaction: the shopper feels like they're talking to a person, not a system.
But tone tests need guardrails. A mismatch between your website's voice and your chatbot's personality feels jarring to shoppers. Test tone within the bounds of your existing brand voice, not outside them.
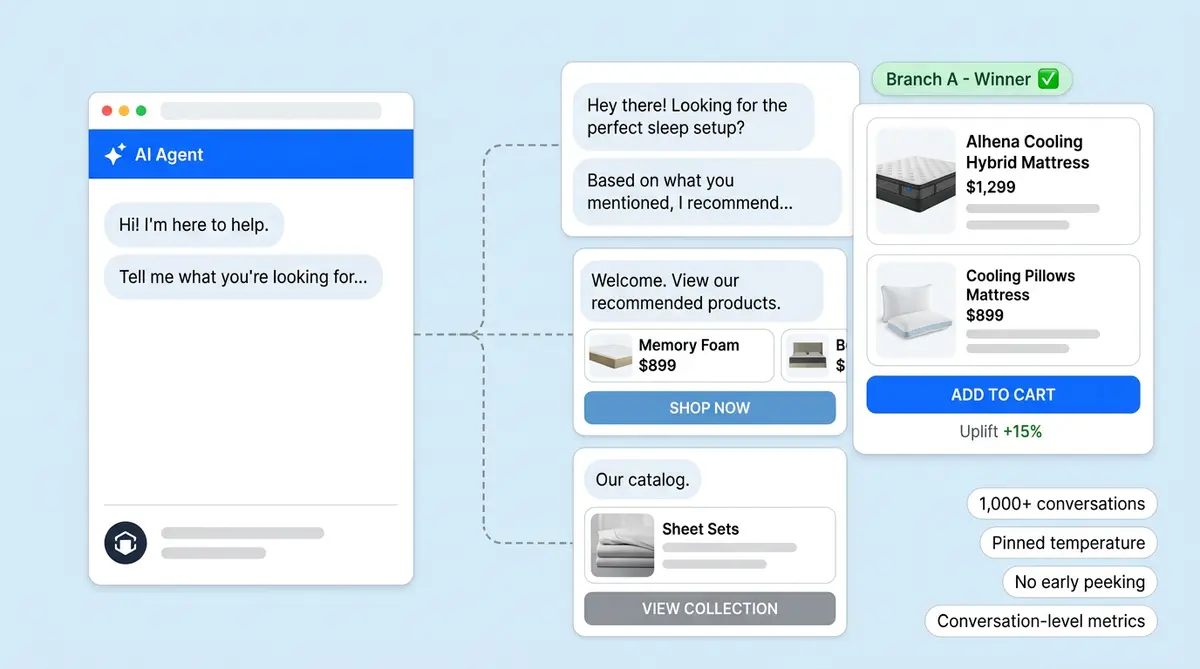
3. Proactive vs. Reactive Engagement
Should your chatbot wait for shoppers to click, or should it start the conversation? This is one of the biggest levers in AI shopping assistant performance. Proactive chatbots reach 45% of site visitors compared to just 5% for passive ones, a 5.5x engagement gap documented in Alhena's proactive engagement analysis.
The conversion data is even more striking. A controlled study of 583 participants found proactive chatbot strategies significantly increased purchase intention (mean score 5.07 vs. 4.42 for reactive, p<0.001). Forrester pegs the ROI difference at 105% for proactive setups vs. 15% for reactive ones.
4. Product Recommendation Logic
Test how your chatbot presents product suggestions. For example:
- Recommendation first vs. needs assessment first (show products immediately vs. ask qualifying questions)
- Single "best match" vs. three-option comparison
- Feature-led vs. benefit-led descriptions ("Contains hyaluronic acid" vs. "Keeps your skin hydrated for 24 hours")
The Chatbase ecommerce case study found that specificity matters enormously: a 12 to 15 percentage point CSAT difference between generic and highly specific base prompts on the same platform, with the same training data. The only difference was how the AI was instructed to frame its answers.
5. Checkout Nudge Timing
When should the AI suggest moving to checkout? Test these trigger points:
- After the first product recommendation
- After the shopper adds an item to cart
- After answering a sizing, shipping, or availability question
- On cart page idle (the shopper stops scrolling for 30+ seconds)
Proactive AI interventions at the right moment recover up to 35% of abandoned carts. Getting the timing wrong, by nudging too early, tanks trust. This is where agentic checkout capabilities that can populate carts and pre-fill checkout fields make a measurable difference: they reduce the steps between "I want this" and "I bought this."
6. Conversation Flow Structure
Test linear flows (the chatbot guides the shopper step by step) against branching flows (the shopper chooses their own path with quick-reply options). Landbot's case studies show that flow structure changes can produce 18% AOV increases and 30% cost-per-lead reductions depending on the use case and audience.
For complex products (electronics, furniture, skincare routines), guided linear flows tend to outperform. For simple repeat purchases, branching flows that let returning shoppers skip the discovery phase convert faster.
7. Prompt Engineering Variations
This is the test most teams overlook. Your chatbot's system prompt (the instructions that tell the AI how to behave) is the single biggest lever you can optimize for response quality. Test variations in:
- Persona assignment (product expert vs. friendly shopping buddy vs. concierge)
- Guardrail strictness (tight scripting vs. giving the LLM more freedom)
- Response length constraints (simplified language drove 33% more sign-ups in one documented test)
Metrics That Matter for AI A/B Testing in Ecommerce
Running a split testing experiment on your chatbot without the right metrics is like running a landing page test and only measuring page views. Here's the measurement framework that marketing and CX teams use to separate useful tests from vanity experiments.
Revenue Metrics (Your North Star)
- Conversion rate: Percentage of chatbot-engaged visitors who complete a purchase
- Average order value: Measures upsell and cross-sell effectiveness across variants
- Revenue per visitor (RPV): Combines CVR and AOV into a single number, the target metric that actually tells you if Variant A makes more money than Variant B
- Cart abandonment recovery rate and recaptured revenue: Critical for exit-intent and proactive intervention tests
Engagement Metrics (Leading Indicators)
- Activation rate: How quickly users respond to the chatbot's first message
- Chat completion rate: Percentage of conversations that reach their intended endpoint
- Fallback rate: How often the chatbot fails to understand or respond, a signal of prompt quality that can help identify where the AI struggles and refine your hypothesis
Satisfaction Metrics (Guardrails)
- CSAT: Post-interaction user experience scores ensure you're not trading customer happiness for short-term conversion
- Customer effort score (CES): How easy the chatbot made it to deliver a great customer experience and user experience, helping the shopper get what they wanted. User experience scores below 80% signal a problem
- Escalation rate: Lower is generally better, but zero is suspicious and usually means the bot is giving bad answers instead of routing to humans
Alhena AI's approach to this is worth noting. Their built-in A/B testing framework tracks add-to-cart value, checkout revenue, and delta calculations between test and control groups automatically. The system uses deterministic fingerprinting so the same visitor always sees the same variant across sessions, which solves the consistency problem that plagues most chatbot A/B setups.
How to Set Up Your First AI Chatbot A/B Test
Here's a step-by-step playbook for running your first structured chatbot experiment. Skip the theory and get to execution.
Step 1: Pick One Variable, Write a Hypothesis
Don't test greeting, tone, and recommendation logic at the same time. Pick one. Write it as: "Changing [variable] from [current state] to [new state] will increase [metric] by [expected amount] because [reason]."
Bad hypothesis example: "A better greeting will improve performance."
Good hypothesis: "A product-specific greeting on collection pages will increase chat completion rate by 15% because it signals relevance before the shopper has to type anything."
Step 2: Calculate Your Required Sample Size
Use Evan Miller's sample size calculator. Plug in your current conversion rate, your pricing tier’s traffic limits, the minimum target improvement you want to detect, and a 95% confidence target, and a 95% confidence target. For most chatbot tests, you'll need 1,000+ conversations per variant.
Divide your monthly chatbot volume by 2 to calculate your effective sample size per variant (each variant gets half the traffic) to estimate how many weeks the test needs to run. Add a buffer for weekday/weekend variation to ensure adequate sample size: always run for at least two full weeks to reach adequate sample size.
Step 3: Instrument and Launch
Ensure your chatbot platform or testing tool can split traffic. The right testing tool tracks per-variant metrics cleanly and track per-variant metrics. Platforms like Alhena AI offer native experiment support where visitors are deterministically assigned to test or control groups and tracked through add-to-cart and checkout events. If your platform doesn't have native A/B testing, you can use your existing testing tool or any split testing tool (Optimizely, VWO, LaunchDarkly) or integrate with your marketing campaigns through platform integration to conditionally serve chatbot variants.
Step 4: Resist the Urge to Peek
Every time a user checks results mid-test and consider stopping, you give randomness another chance to fool you. Set your end date before launch. Don't adjust.
Step 5: Analyze at the Conversation Level, Not the Message Level
A greeting test might look flat at the message level (similar response rates to the first message) but compound into significantly different outcomes, confirming or rejecting your hypothesis by the end of the conversation and directly affect revenue. Always measure at the conversation-level outcome: did this session end in a purchase or drive purchase intent, a cart addition, or an escalation?
Beyond A/B: How AI Is Starting to Test Itself
Traditional A/B testing splits traffic 50/50 and waits. Newer approaches reduce the cost of ai experimentation by automatically routing more traffic to winning variants in real time.
Multi-Armed Bandits for Chatbots
Bain & Company reports that retailers using multi armed bandit (MAB) approaches see "double-digit sales increases" compared to traditional A/B testing. The reason: MAB algorithms "earn while they learn," dynamically shifting traffic in real-time away from underperforming variants instead of wasting half your traffic on the underperformer for weeks.
This real-time adaptation matters more for chatbots than for landing pages. Traditional A/B test variants degrade with repeated exposure (the same message loses effectiveness by the third viewing), while MAB-optimized variants maintain their lift even with daily interactions.
Contextual Bandits for Personalization
Contextual bandits take it further. Instead of finding one winning variant for all shoppers, they serve different variants to different visitors based on real-time user signals: device type, browsing history, location, referral source, time of day, and past customer behavior. The system learns which variant works best for which segment without you having to manually define segments upfront.
Synthetic Testing: Shopify's SimGym
The most radical development in ecommerce ai experimentation is Shopify's SimGym, launched in 2026. It spawns up to 400,000 synthetic shopping sessions per day using AI powered robot shoppers. Merchants can test storefront and chatbot changes in 4 to 10 minutes with zero real traffic. Each synthetic shopper has a persona, budget, and shopping intent trained on billions of real Shopify transactions.
The catch: synthetic buyers currently achieve a 75% task completion rate, and accuracy gaps exist for stores with unusual catalog structures. It's a preview of where ai testing for ecommerce is heading, but not yet a full replacement for real-user experiments.
Five Mistakes That Invalidate Your Chatbot Tests
Even well-designed tests can produce misleading test results. Watch for these pitfalls.
1. Stopping Too Early
You see a 20% lift after 200 conversations and declare a winner based on incomplete test results. Two weeks later, the test results show the effect disappears. Premature test results mislead even experienced teams. This is the "peeking problem," and it's amplified in chatbot testing because conversation volumes are lower and variance is higher than page-view data.
2. Testing Multiple Variables at Once
If you change the greeting AND the recommendation flow AND the checkout nudge timing, you can't attribute the result. Test one variable at a time unless you're running a proper multivariate testing with enough traffic to support it.
3. Ignoring the LLM Temperature Variable
AI powered, LLM-based chatbots produce different responses even with identical prompts. This adds noise that traditional testing frameworks don't account for. During A/B tests, pin your temperature setting or use deterministic outputs so the only variable is the one you're intentionally testing.
4. The Multiple Testing Problem
Adobe's testing documentation spells it out: running 10 tests at 95% confidence gives you approximately a 40% chance of at least one false positive. If you're running parallel chatbot experiments, apply Bonferroni correction or raise your confidence threshold.
5. Not Segmenting by Conversation Type
A test that looks positive on average might be driven entirely by simple "where's my order?" queries while performing worse on complex product discovery conversations. Revisit your hypothesis when you segment test results by user segment, conversation type, intent, and complexity before calling a winner.
What a Real AI A/B Testing Program Looks Like
The brands generating measurable revenue from chatbot experimentation aren't running one-off tests. They're running continuous programs where they run tests. Here's what the cycle looks like at scale.
Month 1: Baseline and Greeting Tests
Establish your current chatbot conversion rate, AOV, and CSAT as baselines. Run your first greeting test as a marketing and ad optimization priority (the highest-ROI starting point, easy to optimize, and one of the clearest benefits of ai testing and benefits of ai optimization). Aim for a sample size of 1,000+ conversations per variant.
Month 2: Tone and Flow Tests
Use your greeting test winner as the new default. Test response tone (formal vs. conversational) or flow structure (linear vs. branching) next. Start tracking revenue per visitor as your primary multivariate testing conversion rate optimization metric.
Month 3: Prompt and Recommendation Tests
Test prompt engineering variations and recommendation logic. By now you run tests with 3+ months of baseline data, making it easier to detect smaller effects.
Ongoing: Shift to Automated Optimization
Once you've exhausted the big manual tests, move to multi-armed bandit or contextual bandit approaches for continuous, automated ways to optimize performance. This is where the compounding effect of experimentation kicks in for your marketing and CX efforts. Alhena's 30-day tuning playbook walks through this progression in detail.
The results are real, showing clear benefits of ai testing at scale and real revenue growth. Tatcha ran a proactive AI engagement program and saw 3x conversion rates, a 38% AOV uplift, and 11.4% of total site revenue flowing through AI-assisted interactions. Victoria Beckham achieved a 20% AOV increase. These aren't chatbot metrics. They're business metrics, the kind that show up in board decks and drive sustainable growth. You can read the full Tatcha case study and Victoria Beckham results for the details.
Key Takeaways
- AI chatbot A/B testing is fundamentally different from the landing page CRO that marketers know because of multi-turn conversations, probabilistic outputs, and lower traffic volumes
- Greeting messages are the highest-ROI test you can run, with documented lifts of 12% to 150% depending on the variant
- Proactive engagement outperforms reactive by 5.5x on reach and converts at 4x higher rates, a gap that marketing leaders can’t ignore
- Minimum 1,000 conversations per variant before drawing conclusions, and always run for at least two full weeks
- Pin your LLM temperature during tests to reduce noise from probabilistic response generation
- Measure at the conversation level (revenue per visitor, not message-level engagement)
- Graduate from manual A/B testing to multi-armed bandits once you've exhausted the big wins
Ready to start running ai ab testing on your ecommerce chatbot? Book a demo with Alhena AI to see how built-in experimentation, revenue attribution, and the real-time analytics Alhena offers, and agentic checkout work together, or start free with 25 conversations to test the experience yourself. Check Alhena’s pricing for plan details.

Frequently Asked Questions
What is AI A/B testing in ecommerce?
AI A/B testing in ecommerce is the practice of running controlled experiments on your AI chatbot's greetings, response tone, conversation flows, and recommendation logic to measure which variants produce higher conversion rates, AOV, and customer satisfaction. Unlike traditional web A/B testing, it accounts for multi-turn conversations and probabilistic AI outputs.
How many conversations do I need for a statistically valid chatbot A/B test?
You need a minimum of 1,000 conversations per variant (2,000 total) to reach statistical significance for most chatbot experiments. For smaller effect sizes (under 5% expected lift), you may need 3,000 to 5,000 per variant. Always run for at least two full weeks to capture weekday and weekend behavior differences.
What should I A/B test first on my ecommerce chatbot?
Start with greeting messages. They're the highest-ROI test because they affect every conversation. Personalized, benefit-driven greetings have shown lifts of 28% in lead capture and up to 150% in mobile signups. After greetings, test proactive vs. reactive engagement triggers, then move to tone and conversation flow structure.
How does chatbot A/B testing differ from landing page A/B testing?
Chatbot tests involve multi-turn conversations with variable user inputs and probabilistic AI responses, while landing page tests involve static content and single interactions. Chatbots also generate lower traffic volumes (conversations vs. page views), require longer test durations, and need conversation-level outcome measurement rather than click-level metrics.
Can AI automate A/B testing for ecommerce chatbots?
Yes. Multi armed bandit algorithms dynamically route more traffic to winning chatbot variants in real time, reducing the revenue cost of testing, unlike an ad campaign that wastes half its budget on the wrong audience. Bain reports that this approach offers retailers see double-digit sales increases vs. traditional 50/50 splits. Shopify's SimGym takes it further with synthetic shoppers that test changes in minutes without real traffic.